논문을 공부하면서 중요한 파라미터중 하나인 Learning Rate를 각각 자신의 방법으로 설계하는 경우를 많이 봤다. 또는, 트랜스포머계열 모형을 공부할때, local minimum에 상대적으로 경건한 cosine warm-up Scheduler를 사용하는것이 일반적이라는 견해도 들었다. 공개된 예시코드로 스케줄러를 건드려본 경험은 있어도 내가 원하는 방식으로 스케줄러를 조절해 본 기억이 없어, 어떻게 조절하는지 궁금해 scheduler에 대해 공부하게 되었다.
공부 참고 링크 : https://gaussian37.github.io/dl-pytorch-lr_scheduler/
0. 공부 준비
먼저 가장 기본적인 코드를 구성하고 시작하자. 간단한 형태의 모델과 옵티마이저를 구성하고, 간단한 stepLR 스케줄러를 이용하여 learning rate 변화를 추적하고 시각화 해보자.
# 가장 간단한 형태의 model과 optimizer
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
model = nn.Linear(10, 1)
optimizer = optim.SGD(model.parameters(), lr=0.1)# StepLR scheduler
step_size = 10
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size = step_size, gamma = 0.5)
# epochs 설정, 스텝마다 lr을 추척하며 값을 담을 리스트 lrs를 생성
num_epochs = 50
lrs = []
# lrs에 각 스텝마다의 lr 저장 (param_groups, step)
for epoch in range(num_epochs) :
lrs.append(optimizer.param_groups[0]['lr'])
scheduler.step()
# lr 변화 시각화
plt.figure(figsize=(10,6))
plt.plot(lrs)
plt.xlabel('Epoch')
plt.ylabel('Learning Rate')
plt.title('Learning Rate Scheduler')
# step_size마다 수직 점선
for epoch in range(0, num_epochs, 10):
plt.axvline(x=epoch, color='red', linestyle='--', linewidth=1)
plt.show()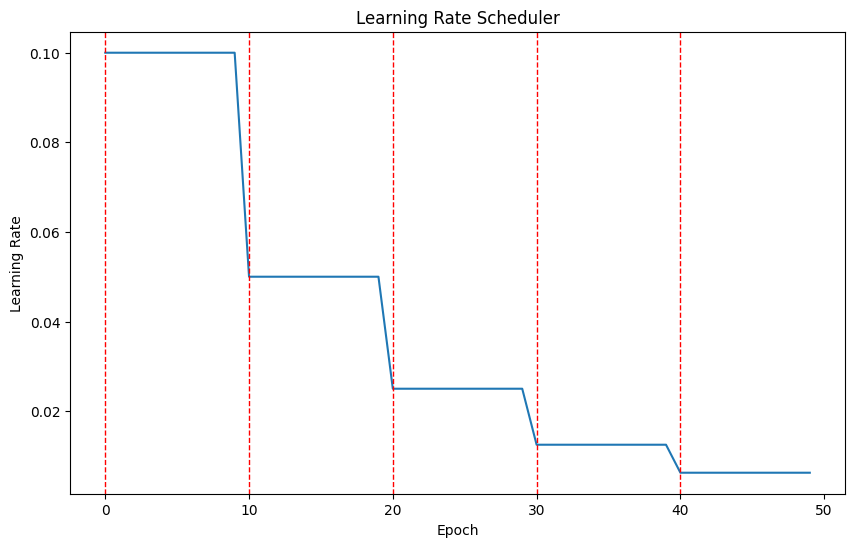
1. Param_groups
먼저 param_groups에 대해 알아보자. 이는, 위의 코드에서 lr값의 변화를 추적할때 사용하는 함수이며, 이후에 나올 scheduler에 대해 실제 코드를 살펴볼때 계속 나오는 개념이라 먼저 정리하고자 한다. 'Parameter Group'은 optimizer에서 관리하는 파라미터들의 그룹을 의미한다. 이를 호출해 optimizer에서 관리하는 변수들에 접근, 수정 및 최적화가 가능하다.
예를들어 두개의 층을 갖는 단순 모형에 대해 param_groups를 살펴보자.
import torch.nn as nn
import torch.optim as optim
# 간단한 모델 정의
model = nn.Sequential(
nn.Linear(10, 50),
nn.ReLU(),
nn.Linear(50, 1)
)
# optimizer 설정 시 다른 learning rate을 사용하는 두 개의 parameter group 설정
optimizer = optim.SGD([
{"params": model[0].parameters(), "lr": 0.001}, # 첫 번째 레이어는 learning rate 0.001로 설정
{"params": model[2].parameters()} # 두 번째 레이어는 기본 learning rate (예: 0.01)로 설정
], lr=0.01)
이때의 optimizer.param_groups는 아래와 같이 구성된다.
[
{
'params': [ ... ], # 첫 번째 레이어의 파라미터 (텐서 객체들의 리스트)
'lr': 0.001,
'momentum': 0, # SGD optimizer의 기본값
'dampening': 0, # SGD optimizer의 기본값
'weight_decay': 0, # SGD optimizer의 기본값
'nesterov': False, # SGD optimizer의 기본값
...
},
{
'params': [ ... ], # 두 번째 레이어의 파라미터 (텐서 객체들의 리스트)
'lr': 0.01, # 기본 learning rate
'momentum': 0, # SGD optimizer의 기본값
'dampening': 0, # SGD optimizer의 기본값
'weight_decay': 0, # SGD optimizer의 기본값
'nesterov': False, # SGD optimizer의 기본값
...
}
]
즉, 처음 lr 값을 추적할 때 사용했던 모델은 한층짜리 Linear 모델이었으므로, optimizer.param_groups[0]['lr'] 은 첫 Linear 층의 파라미터 중 lr값을 직접적으로 호출하는 것이다.
2. LambdaLR
개인적으로 굉장히 신기한 scheduler이라 생각한다. jinsol 님의 표현을 빌리자면 lambdaLR 스케쥴러는 가장 유연한 스케줄러로서, lambda 함수 및 func 을 통해 직접 스케줄링 함수를 구현해줄 수 있다.
제공해주신 예제 세가지를 살펴보면 아래와 같다.
1. lambda 함수를 통한 스케줄링
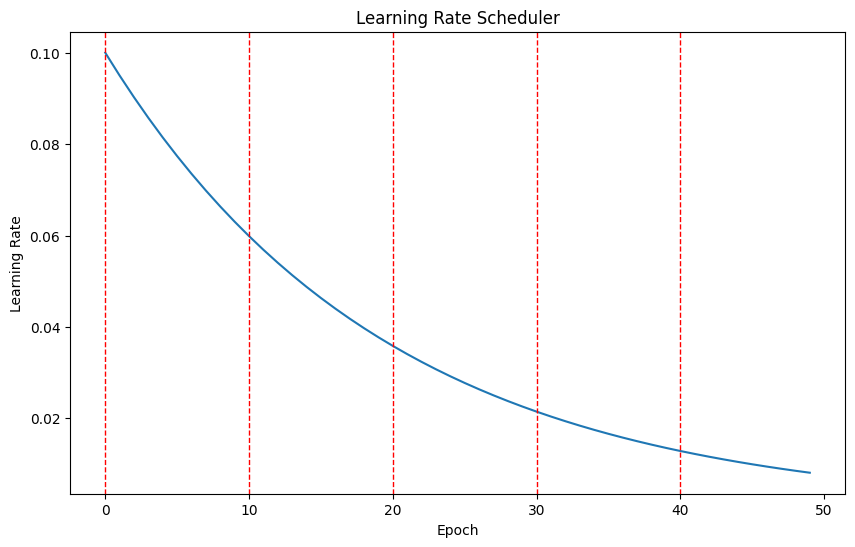
scheduler = LambdaLR(optimizer, lr_lambda = lambda epoch: 0.95 ** epoch)이와 같이 구성하면, 스케줄러는 초기 lr 값에 0.95^(epoch) 를 곱해준만큼, 즉 에포크마다 지수적으로 감소하는 스케줄러를 구성한다.
2. func 을 활용한 scheduler
def func(epoch):
if epoch < 10:
return 0.5
elif epoch < 20:
return 0.5 ** 2
elif epoch < 30:
return 0.5 ** 3
else:
return 0.5 ** 4
scheduler = LambdaLR(optimizer, lr_lambda = func)이렇게 lr_lambda 함수를 구성하면 각 에포크별로 scheduler 값이 달라지며, 이는 위와같이 초기 lr값에 가중치처럼 곱해져 학습률이 적용된다.

즉, epoch를 매개변수로 하여 실수를 return하는 함수를 구성하면, 함숫값과 base lr을 곱한 값이 학습률로 적용되는 매커니즘만 이해한다면, 이와같이 커스텀 함수를 구성하여 내가 원하는 방식대로 스케줄러를 구성해 줄 수 있다.
원래는, 클래스 상속을 통한 warmup scheduler를 구성하는 코드가 예제로 있지만, 먼저 func를 이용한 코드도 구현해 보았다. 이러한 warmup 방식은, 특정 max값을 넘을 경우 이를 max값으로 대체하여 크기를 조절하는 clipping방식이며, gradiant clipping 이라고도 한다.
import torch.optim as optim
#initial lr에서 final lr까지 서서히 lr값이 증가하다가, final lr에 도달하면 값 유지
def warmup_scheduler(epoch, warmup_epochs=10, initial_lr=0.01, final_lr=0.1):
if epoch < warmup_epochs:
# warmup 단계에서는, learning rate가 선형적으로 증가
return (final_lr - initial_lr) / warmup_epochs * epoch + initial_lr
# 웜업 이후에는 final_lr을 반환
return final_lr
optimizer = optim.SGD(model.parameters(), lr=0.01)
scheduler = optim.lr_scheduler.LambdaLR(optimizer, lr_lambda = warmup_scheduler)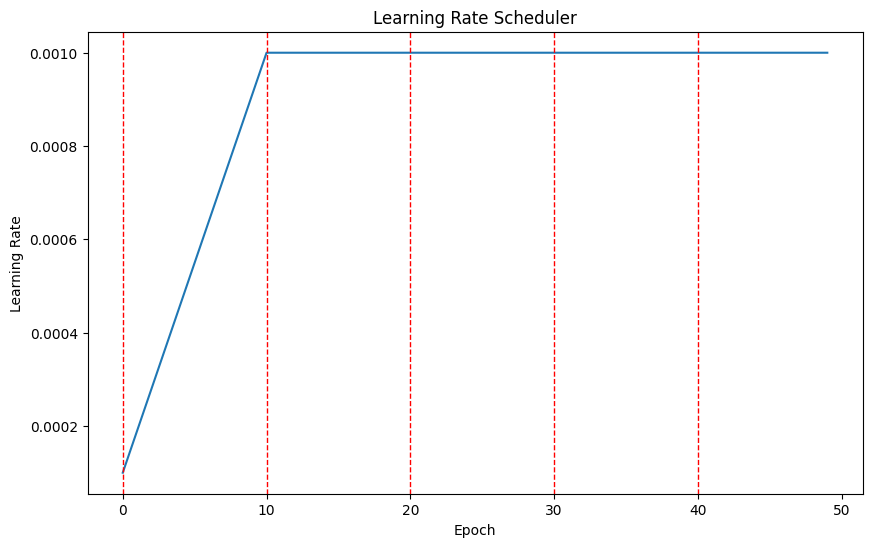
3. 클래스 상속을 통한 스케줄러 클래스 구현
jinsol 님 코드를 살펴보면, lambdaLR 함수를 부모클래스로 불러와 class 상속을 통해 lambdaLR의 메서드들을 자연스럽게 사용하고 있다. 이렇게 클래스로 구현해 놓으면, 자신의 custom scheduler 를 아래와 같이 간단하게 모듈화하여 사용할 수 있다.
class WarmupConstantSchedule(optim.lr_scheduler.LambdaLR) :
def __init__(self, optimizer, warmup_steps, last_epoch = -1) :
# last_epoch는 LambdaLR 의 변수로, 에포크가 몇번째 진행되었는지를 의미, -1이 초기값으로 이때는 init 진행
def lr_lambda(step) :
if step < warmup_steps : # step 메서드 역시 LambdaLR 에서 정의
return float(step) / float(max(1.0, warmup_steps))
return 1.0
super(WarmupConstantSchedule, self).__init__(optimizer, lr_lambda, last_epoch = last_epoch)
optimizer = optim.SGD(model.parameters(), lr=0.01)
scheduler = WarmupConstantSchedule(optimizer, warmup_steps=10)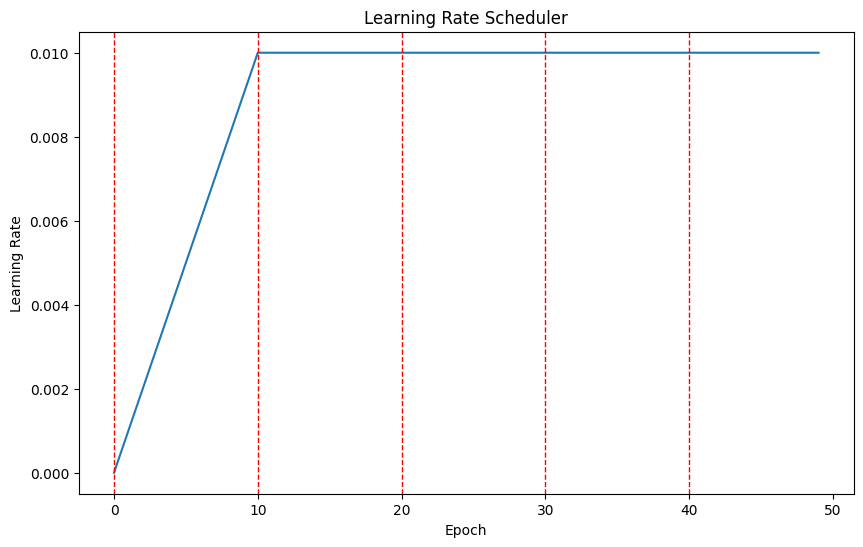
+ pytorch optim 함수를 통해 LambdaLR 이해하기
링크 : https://github.com/pytorch/pytorch/blob/v1.1.0/torch/optim/lr_scheduler.py#L56
LambdaLR에 대해 알아보며, 일단 가장 처음으로 epoch에 대한 함수를 lr_lambda에 넣으면 어떻게 lr값이 조정되어 나오는지, 그리고 lambda 함수로 구현을 해도 되고, func 로 각 상황에 대한 지정값을 넣어줘도 동작하는게 신기해서 pytorch 코드를 직접 살펴보게 되었다.
LambdaLR 는 init 에서, 각 에포크마다 계산될 LR 가중치 함수를 LR 갯수만큼 생성한다. 이때 각 층의 LR에 서로 다른 scheduler를 적용하고 싶다면, lr_lambda에 함수를 리스트 또는 튜플로 제공하면 된다. LR 의 갯수는 param_groups 를 활용하여 간단하게 계산 가능하다. 단, 서로 다른 LR에 개별적으로 스케줄러를 지정하고 싶다면, LR 갯수와 동일한 길이의 함수 리스트를 구성해야 한다.
스케쥴러로 조절된 LR 값은 최종적으로 LambdaLR 클래스 내부 get_lr 함수를 통해 구현되는데, 상속받는 _LRScheduler클래스 내부의 초기 LR을 보관하고있는 self.base_lrs를 호출한 이후, 현재 epoch 값을 그대로 사용자 지정 함수 lr_lambda에 넣어 LR 가중치를 계산, 이를 각각의 self.base_lrs에 곱함으로서 스케쥴링된 LR을 계산해낸다.
pytorch 코드
class LambdaLR(_LRScheduler):
"""Sets the learning rate of each parameter group to the initial lr
times a given function. When last_epoch=-1, sets initial lr as lr.
Args:
optimizer (Optimizer): Wrapped optimizer.
lr_lambda (function or list): A function which computes a multiplicative
factor given an integer parameter epoch, or a list of such
functions, one for each group in optimizer.param_groups.
last_epoch (int): The index of last epoch. Default: -1.
Example:
>>> # Assuming optimizer has two groups.
>>> lambda1 = lambda epoch: epoch // 30
>>> lambda2 = lambda epoch: 0.95 ** epoch
>>> scheduler = LambdaLR(optimizer, lr_lambda=[lambda1, lambda2])
>>> for epoch in range(100):
>>> train(...)
>>> validate(...)
>>> scheduler.step()
"""
def __init__(self, optimizer, lr_lambda, last_epoch=-1):
self.optimizer = optimizer
if not isinstance(lr_lambda, list) and not isinstance(lr_lambda, tuple):
self.lr_lambdas = [lr_lambda] * len(optimizer.param_groups)
else:
if len(lr_lambda) != len(optimizer.param_groups):
raise ValueError("Expected {} lr_lambdas, but got {}".format(
len(optimizer.param_groups), len(lr_lambda)))
self.lr_lambdas = list(lr_lambda)
self.last_epoch = last_epoch
super(LambdaLR, self).__init__(optimizer, last_epoch)
""" 중간 생략 """
def get_lr(self):
return [base_lr * lmbda(self.last_epoch)
for lmbda, base_lr in zip(self.lr_lambdas, self.base_lrs)]
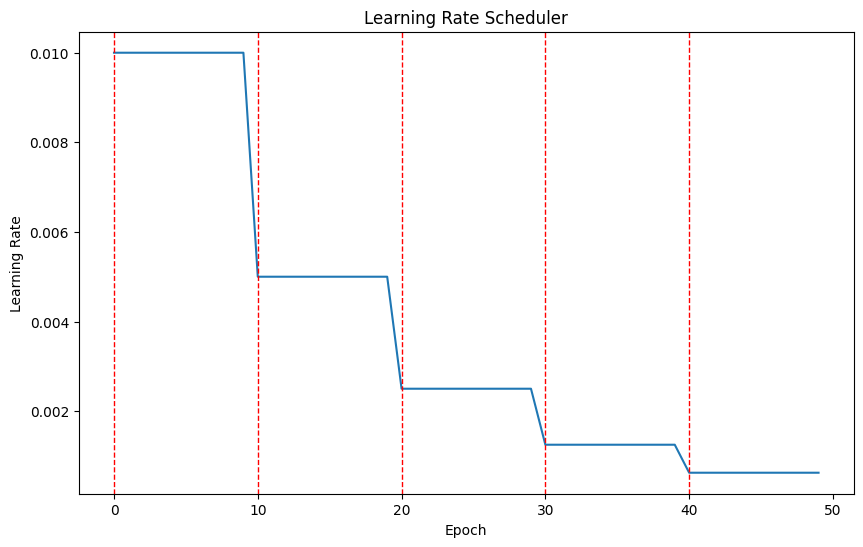
3. StepLR
일정 고정된 epoch step을 지날 때 마다 gamma가 LR에 곱해짐. (일정 주기로 지수적으로 감소)
optimizer = optim.SGD(model.parameters(), lr=0.01)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.5)
4. MultiStepLR
StepLR과 유사하게 지정 epoch step을 지날 때 마다 gamma가 LR에 곱해지나, step을 자율적 기준으로 세세하게 조정 가능하다. (원하는 step size를 list로 주어, 지정된 스텝을 지날 때 마다 지수적으로 곱해짐)
optimizer = optim.SGD(model.parameters(), lr=0.01)
scheduler = optim.lr_scheduler.MultiStepLR(optimizer, milestones=[20, 35], gamma=0.5)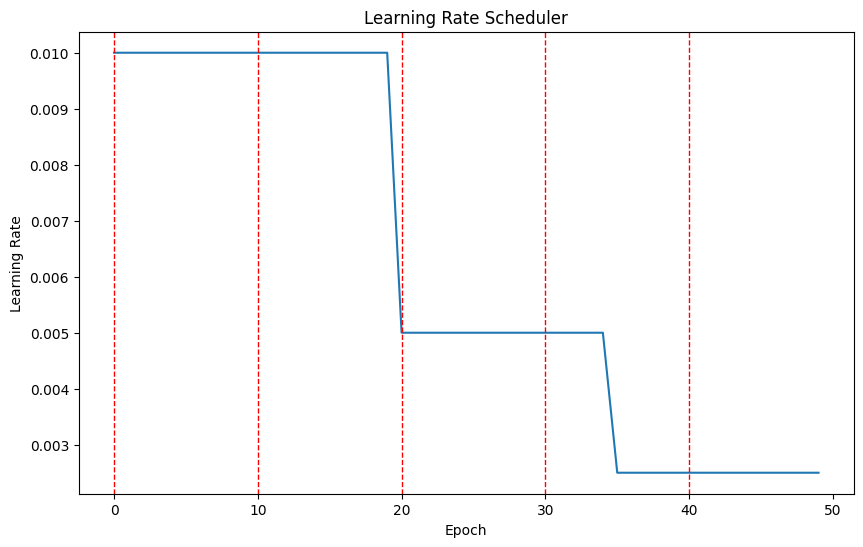
'머신러닝 & 딥러닝' 카테고리의 다른 글
| 데이터 인코딩, 기존에 등록되지 않은 변수가 입력된 경우 (0) | 2024.02.04 |
|---|---|
| [공부기록] 부스팅(Boosting) 모델 간단 리뷰 (AdaBoost, Gradient Boost, XGBoost) (0) | 2023.12.22 |
| MLOps 환경 구축 예시 (0) | 2023.12.13 |
| Object detection 개요 및 모델 설명 (0) | 2023.09.05 |
| 모델 서빙 비교 (0) | 2023.03.17 |