0. 개요
간단한 <벽돌 깨기 게임> 플레이 로그데이터를 바탕으로, 각 레벨 스테이지의 난이도를 계산하는 프로젝트를 진행했습니다. 본 테스크는 kaggle - "Arcade Game Stats" 를 기반으로 진행하였으며, 테스크 목적은, 제작된 Level-000 총 19개 스테이지에 대해 오토 봇 플레이를 6,814 번 진행했을 때, 이 플레이 로그를 바탕으로, 19개의 맵의 난이도 순서를 측정하는 테스크입니다.

<제공 데이터>
- Date: 게임이 오토 플레이된 날짜와 시간
- Level: 레벨명 (3자리 숫자는 이전 실행의 난이도 추정치로, 조정 후에는 더 이상 유효하지 않음)
- NumBlocks: 레벨을 클리어하기 위해 깨야 하는 블록의 수
- IsWin: 자동 재생이 모든 블록을 깼다면 True(클리어), 공이 패들 밑으로 떨어졌다면 False(실패)
- ElapsedTime: 승리 또는 패배까지 걸린 시간(게임이 4배속으로 재생되므로, 사람이 플레이하는 시간을 추정하려면 4를 곱해야 함)
- Score: 게임에서 승리하거나 패배했을 때의 총 점수
- Accuracy: 자동 재생은 무작위로 선택된 정확도로 조정됨. 높은 숫자일수록 승리할 가능성이 높음

Level은 기존에 임의로 지정해놓은 스테이지 레벨로, 차후 본 테스크의 결과에 따라 스테이지 명과 스테이지 순서가 바뀔것으로 예상됩니다.
또한, 오토 봇은 완벽하진 않지만, 정확도를 랜덤하게 지정하여 Accuray 라는 이름으로 저장되어 있습니다. 즉 이 값이 본 스테이지에 진입한 유저의 실제 실력지표라고도 평가해볼 수 있습니다.
<테스크 원문>
https://www.kaggle.com/datasets/depmountaineer/arcade-game-stats
Arcade Game Stats
Statistics on a Blockbreaker-like Game
www.kaggle.com
About Dataset
Statistics on a Blockbreaker-like Game
The author is in the process of creating a blockbreaker-like game, in which the jumping-off point is the "Block Breaker" section of the Udemy course, Complete C# Unity Developer 2D: Learn to Code Making Games
After making lots of levels, the author needed to sort them by difficulty. How does one measure the difficulty of a level? A first-cut solution is
to make an auto-play bot that is not perfect, and see how well the bot does on each level, using thousands of trials.
Here is a video of the game in auto-play action.
Fields
- Date: date and time the game was auto-played
- Level: the name of the level (the 3-digit number is an estimate of the difficulty from a previous run, no longer valid after tweaking)
- NumBlocks: how many blocks have to be broken to win the level
- IsWin: True if autoplay broke all the blocks, False if the ball fell past the paddle.
- ElapsedTime: Seconds until either won or lost (game is played at 4x speed, so multiply by 4 to get an estimate of how long a human might play it)
- Score: total score when the game was won or lost
- Accuracy: the autoplay is tuned with a randomly-chosen accuracy. Higher numbers are more likely to win.
1. 게임의 어려움(Difficulty)의 정의
게임의 어려움이란 어떻게 정의할 수 있을까요?
퍼즐 게임류 라는 것을 생각해 봤을 때, 퍼즐 자체의 난이도가 있을 수 있고, 유저의 실력, 블럭의 수, 블럭 배치, 맵의 복잡도 등도 있을 것입니다. 이를 크게 아래와 같이 4가지의 어려움으로 정리해 봤습니다.

여기서 난이도의 어려움을 적절하게 측정하고 레벨 순서를 난이도별로 잘 배치한다면, 각 맵을 클리어하며 성장하는 유저들에 맞게 난이도가 조절되어, 게임을 즐기는 유저에게 꾸준한 성취감을 제공할 수 있고,
반대로 맵의 복잡성을 적절하게 측정한다면, 맵의 퀼리티와 유저 피로도를 계산할 수 있습니다. 이를 활용하면, 목표치가 높은 특정 레벨을 보스전으로 구성할 수도 있고, 클리어까지 플레이 타임이 너무 길다던지, 목표치가 너무 높게 설정된 게임 맵들을 적절하게 밸런스 조취를 취할 수 있을것입니다.
2. 난이도 수치화
(1) EDA
데이터는 아래와 같이 주어져 있습니다.
데이터 수집 기간은 2019-09-07 ~ 2019-09-09 3일, 총 6,184건의 오토 봇 플레이 로그가 기록되어 있습니다.
Accuracy는 각 플레이 로그에서 랜덤으로 지정된 봇의 실력지표이고 0.0~0.4 사이의 값을 가집니다.
EDA 결과 봇의 시간대별 Accuracy 차이는 없으며, 이 외에도 시간에 따른 직접적 변화를 갖는 변수가 없어 Date 열은 삭제, 대신 각 레벨별 일별 난이도 추이를 살펴보기 위해 Day 열을 추가적으로 생성하였습니다.
block_game_all = pd.read_csv('/content/drive/MyDrive/DACON/블럭깨기 게임/GameStats.csv',
parse_dates = ['Date']).sort_index()
block_game_all['Day'] = block_game_all['Date'].dt.date
block_game_all.drop(columns=['Date'], inplace=True)
block_game_all
# print(block_game_all.info())
# print("\n", block_game_all.describe())
# print("\n", block_game_all.shape)
# sns.heatmap(block_game_all.isnull())

먼저, 각 레벨 별로 사용된 봇의 Accuracy 분포가 동일한지 살펴보았습니다. 이는 이후에 각 레벨별 클리어율을 이용해 난이도를 비교할 계획이기 때문입니다. 그러므로 그 이전에, 각 레벨별로 사용된 봇의 실력이 독립적이며 그 분포가 유사한지 살펴볼 필요가 있었습니다.
이에, 사분위수, violin_plot 을 같이 활용하여 살펴보겠습니다.
g = block_game_all.groupby(['Level'])["Accuracy"]
# 각 맵별 봇 Accuracy 분포 - 사분위수
level_describe = pd.DataFrame({
'Level': g.mean().index.get_level_values('Level'),
'Mean': g.mean(),
'Median': g.median(),
'Std': g.std(),
'Min': g.min(),
'Max': g.max(),
'count' : g.count()
}).reset_index(drop=True)
level_describe
# 각 맵별 봇 Accuracy 분포 - violin_plot
sns.violinplot(x='Accuracy', y='Level', data=block_game_all)
plt.title("Bot's Accuracy by Level")
plt.show()
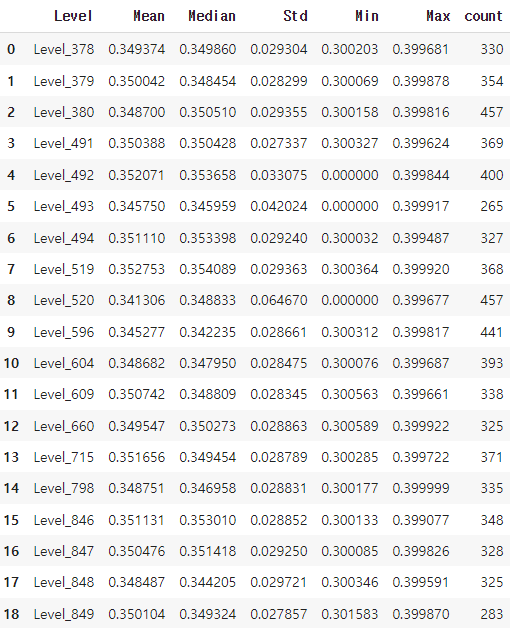
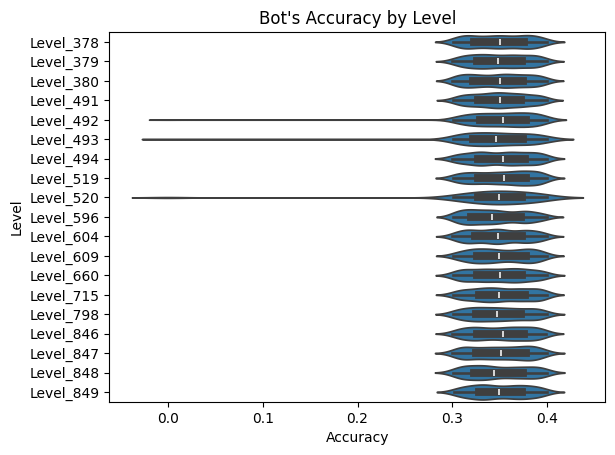
각 레벨 스테이지에 따라 사용된 봇의 Accuracy, 봇의 플레이 수 역시 각 스테이지별로 충분히(250회 이상) 수행되었음이 나타났습니다. 즉 각 스테이지 레벨 별로 활용된 봇의 실력은 그 분포가 유사하다고 볼 수 있겠습니다.
(2) 난이도와 요구 실력치 계산
맵의 난이도는 직접적인 측정은 힘들지만, 일반적인 게임 관행으로서 클리어율이 낮은 맵일수록 높은 난이도의 맵으로 계산되곤 합니다. (ex 슈퍼마리오 메이커)
(물론 예시와 같은 게임에서는 너무 낮은 성공률의 맵은 필터링, 맵의 유저 평가 등을 함께 고려하여 맵을 평가하지만, 이는 '맵의 복잡성'에서 다뤄볼 주제이며, 일단은 레벨의 난이도 나누기에 집중해봅시다.)
즉, 게임의 난이도가 높다는 것은 게임의 클리어 실패율이 높다는 의미이며 이 둘은 어느정도 양의 상관관계를 갖습니다. 따라서 아래와 같은 방식으로 난이도(Difficulty) 를 계산해 보겠습니다.
$$ Difficulty = \left ( 1-p \right ) * 1000 $$
다음으로, 클리어 요구 실력치는 다음과 같이 계산되었습니다.
봇의 클리어 실패 사례는 의미가 없다고 판단하여 클리어 비율을 따지기보단, 클리어 성공 사례에 대해 봇의 실력(Accuracy)의 대표값을 추출하고자 했습니다. 대표값으로는 중앙값(median) 을 활용했습니다.
이를 계산한 알고리즘은 아래와 같습니다.
# Difficulty : 게임 난이도 지수 = (1-클리어율) * 1000
g = block_game_all.groupby(['Level', 'Day'])[['IsWin']]
win_rate = g.mean()
s = pd.DataFrame({
'Level': win_rate.index.get_level_values('Level'),
'Day': win_rate.index.get_level_values('Day'),
'Difficulty': np.round((1 - win_rate) * 1000, decimals=0).squeeze()
}).reset_index(drop=True)
# 원본 DB에 merge
block_game_all = pd.merge(block_game_all, s, on=['Level', 'Day'])
block_game_all# Date, Level을 인덱스로 변환
block_game_all = block_game_all.set_index(['Level','Day'])
# 요구 난이도 게산
means = block_game_all.groupby(level="Level").mean().sort_values('Difficulty')
means['ThresholdAccuracy'] = 0
for level in means.index:
l = block_game_all.loc[level]
r = np.linspace(l.Accuracy.min(), l.Accuracy.max(),100)
for x in r:
left = l[l['Accuracy'] < x]
right = l[l['Accuracy'] > x]
if left['IsWin'].sum() >= right['IsWin'].sum():
means.loc[level,'ThresholdAccuracy'] = x
break
means

(3) 레벨 별 난이도 분석 및 시각화
각 레벨 별 난이도(Diffculty)와 클리어 요구 실력치(ThresholdAccuracy)는 아래와 같은 추이를 보입니다.
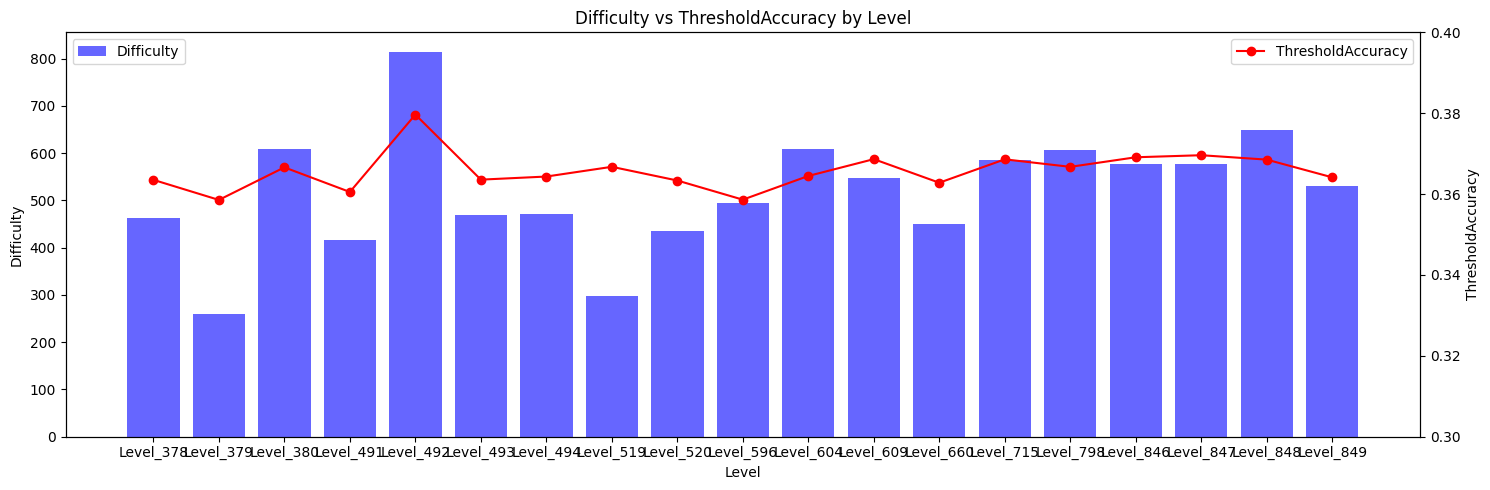

그래프 상 수치까지 표시되진 않지만, 가장 높은 난이도를 가진 Level_492 의 경우 평균 클리어율 18%를, 가장 난이도가 낮은 것으로 보이는 Level_379의 경우 클리어율 74%를 보여주고 있습니다. 또, 두번째 그래프와 같이, 맵을 난이도 순으로 정렬해 봤을 때 난이도가 높아질수록 클리어 요구 실력치 역시 유사하게 높아지는 추세를 갖고 있는것으로 확인됩니다.
다만 추세를 벗어나는 Level_519번 같은 경우, 클리어율과 요구 난이도가 모두 높은 것으로 봤을 때, 어느정도의 수준을 가진 유저들에게는 매우 쉽게 느껴질 수 있는 난이도로 판단됩니다.

추가적으로 일별 난이도 편차를 보기 위해 3일 간 난이도 추이를 위와같이 동시 비교해봤습니다. 각 레벨별 난이도는 등락 패턴을 보이긴 한나, 전반적으로 어려운 맵들은 꾸준히 높은 난이도를 유지하고 있음이 확인됩니다.
3. 맵 복잡성 수치화
(1) 맵 내 블록수가 많을수록 난이도에 영향을 미칠까?
블록깨기 게임을 생각해 봤을 때, 일반적으론 깨야할 목표 블록 수가 많으면, 플레이 시간도, 유저들이 체감하는 난이도와 피로도는 증가할 것이라 생각할 수 있습니다.
그러나, 아래와 같은 컨셉이 담긴 맵들은, 비록 목표 블록수가 많더라도, 제작 의도나 컨셉에 따라 난이도와 재미를 조절할 수 있습니다. 예를들어, 어떤 맵은 목표 블록 수가 적음에도 배치의 복잡성 때문에 어려움을 느낄 수 있고, 어떤 맵은 기가막힌 설계로 목표 블록이 많더라도 시원하게 팍팍 줄어드는 맵일 수 있는 셈이죠.
다만, 유저들이 실제 의도대로 게임을 즐기고 있는지는 플레이 로그데이터를 살펴볼 필요가 있습니다.



Q. 게임 내 목표 블록 수가 많으면 어려운가?
아래는, 게임 내 목표 블록 수와, 클리어 타임/난이도/요구 실력 간 상관관계를 분석한 그래프입니다. 회귀 모델 적합시 상관 계수 $ R^{2}$가 각각 0.7, 0.6, 0.6으로 높은 상관성을 보여줍니다. 그럼, 정말 블록 수가 많을수록 유저가 어려움을 느끼는걸까요?
여기서 유의해야할 점은 바로 100개가 넘는 목표 블록수를 가진, Level_492번 맵입니다. 이 점이 오른쪽 상단을 차지하고 있어 이 선이 유의미하게 보일지 모르겠지만, 이 선이 빠졌을 때도 과연 회귀선이 아래와 같이 추정될까요?



블록 수가 100개가 넘는 이상치 맵을 제거해본 결과, 레벨 내 블록수는 클리어 타임/난이도와 0.3 정도의 낮은 상관관계를, 블록수와 요구 실력 간에는 상관관계가 없는 것으로 나타났습니다.
즉 맵에 설치된 블럭이 많아진다고 해서, 맵 난이도가 이에 비례하여 높아지는 것은 아닙니다. 다만, 레벨 난이도를 설계한 기획자의 입장에서는, 블럭이 많아질수록 벨런스를 맞추기 어렵기 때문에, 이런 컨셉 맵들이 제작 의도에 맞게 클리어율이 유지되고 있는지 지속적인 모니터링이 필요할 것입니다.



(2) 클리어 타임이 길면 난이도에 영향을 미칠까?
그러나 승리 게임에 대해서 클리어 타임은 난이도와 꽤 높은 상관관계를 갖는 것으로 보입니다. 역시 이상치를 제거한 데이터에 대해, 클리어 타임과 난이도 간 상관관계는 0.7, 클리어 타임과 요구 실력간 상관관계는 0.4 정도로, 클리어 타임이 길어질수록 클리어율은 낮아지는 모습을 보입니다.
이는 봇 특성상, 게임이 길어질수록 실수를 할 확률이 증가하는 자연스러운 현상일 수도 있지만, 클리어 타임이 난이도를 대변할 수 있는 하나의 지표가 될 수 있음을 시사하기도 합니다.

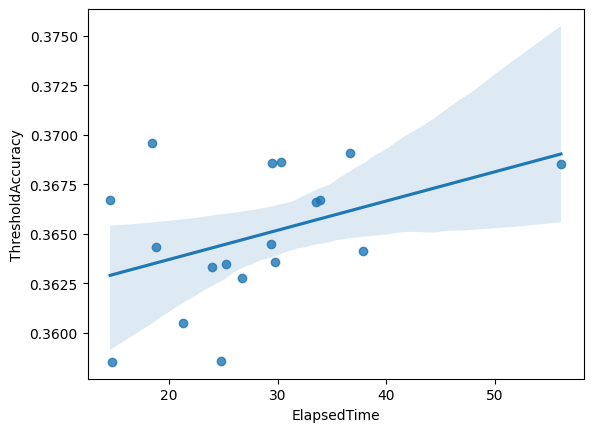
더불어, 게임 설계 단계에서 설계한 맵 난이도와, 실제 클리어 타임, 유저 체감 난이도 등을 적절하게 비교하여, 목표와 다르게 플레이되고 있는 맵에 대해서는 난이도 조정 패치를 진행할 필요가 있겠습니다.


'프로젝트 > 캐글 경진대회 스터디' 카테고리의 다른 글
| [kaggle] 이커머스 고객 행동 로그 분석 part 2. (분석 목표 : 방문 1시간 이내 즉시 구매고객의 전환 요인 분석) (0) | 2024.12.04 |
|---|---|
| [kaggle] 이커머스 고객 행동 로그 분석 part 1. (분석 목표 : 전환 과정의 pain-point 탐색 및 개선) (1) | 2024.12.02 |
| [DACON] "이커머스 고객 세분화 아이디어 보고서" - RFM/선호 카테고리/구매 패턴 기반 고객 세분화 전략 (0) | 2024.03.03 |
| [Dacon] "학습 플랫폼 이용자 구독 갱신 예측" .part5 (분석 보고서) (0) | 2024.01.21 |
| [Dacon] "학습 플랫폼 이용자 구독 갱신 예측" .part4 (소비자 유형 분석) (0) | 2024.01.15 |