[Dacon] "학습 플랫폼 이용자 구독 갱신 예측" .part4 (소비자 유형 분석)
part 4에서는 비지도학습 군집화 방식을 활용하여 구독 유저들의 특성에 따라 세분화를 진행하고, 각 그룹별 특성을 파악하여 유의미한 비지니스적 결론을 도출해 내보고자 하였다.
유형 분석 방법론으로는, 기존에 공부했던 논문, 고객 리뷰 평점 중심 소비자 유형분석 논문의 분석과정을 다수 차용하여 분석에 활용하였다.
0. 분석 결과
분석 목표 : 고객 세분화를 통한 맞춤형 구독 전환 프로모션 마케팅 전략 수립
분석 설계
- 군집화에 있어 유의 변수에 있어 class 데이터간의 밀도차이가 존재한다는 가설을 증명하기 위해 DBSCAN을, 연속형&범주형 변수를 모두 활용한 군집화 방식으로 ward linkage 방식을 채택하였음.
- 유의미한 군집 갯수 선정 및 군집의 유의성 판단을 위해 1) dendrogram을 활용한 안정성 판단 2) silhouette score 계산 3) 각 군집간 target에 대한 개별 분류모델 모델링 결과가 서로 다른지(논문 방식) 를 근거로 활용하였음.
- 각 군집 특성을 Box-plot을 활용하여 비교하고, 이를 통해 각 군집에 대한 맞춤 마케팅 전략을 수립하였음.
분석 결론
- DBSCAN 분류 결과, 선호 난이도 및 성취도 측면에서 매우 높은 이상치를 보이는 '학습 열의가 매우 높은 그룹 B'를 탐색했으며, 대부분 다음달 '구독을 연장'한 유저였음.
- ward-linkage 분류 결과, 낮은 학습 참여도, basic 구독 형태 선호, 구독 연장 비율이 1% 수준의 특징을 보인 그룹 A vs 높은 '평균 학습 세션 유지 시간' 을 보유하고 구독 연장 비율이 100%에 가까운 그룹 B vs 높은 학습 성취도, Premium 구독 형태 선호, 구독 유지율이 60% 이상인그룹 C 을 탐색할 수 있었음
- (ward-linkage) 구독 연장률이 현격히 낮은 그룹 A 유저는 전체 구독자 중 약 56%로, 구독 연장률을 높이기 위하여 그룹 A의 특성을 파악하고 맞춤형 연장 전략을 수립하는것이 효율적이다.
- (ward-linkage) 그룹 A 에 대한 구독 연장 여부에 대한 XGB 모델링 결과, 구독 연장 예측에 가장 영향을 끼치는 변수로 '평균 로그인 유지시간', '최근 학습 성취도', '평균 로그인 시간' 으로 확인되었고, 이 변수 지표를 높일 수 있는 프로모션을 진행하여 구독 연장률을 따라 높이는 전략을 취할 수 있다. (반복적인 접속을 유도할수 있는 동기부여 형성, 접속을 유지할 수 있도록 하는 장치)
1. 밀도 기반 군집 분석
1-1. 분석 과정
밀도기반 군집을 가장먼저 생각하게 된 근거는 크게 두가지로,
- 데이터가 갖고 있는 이상치들이 다수 존재, 이러한 이상 데이터 그룹은 어떤 특성을 갖고 있을까?
- EDA 에서 살펴본 구독 연장/취소 유저 분포에서, 일반적인 학습 관련 변수들에서 압도적으로 높은 이상치들을 가진 데이터 그룹이 거의 구독을 연장하는 패턴을 파악하였음, 이를 이상치 기반으로 탐색하면 유의미한 의미를 갖는 그룹을 분리해낼 수 있지않을까?
이를 위해 밀도 기반 군집분석 DBSCAN을 떠올리게 되었다.

위와같이 DBSCAN 은 인접 데이터의 공간상 밀도를 기준으로 뭉쳐있는 데이터를 같은 그룹으로 묶어내는 방식이며, 이에대한 강점으로, 정상적인 데이터 군집과 멀리 떨어진 이상치 그룹을 쉽게 분리해내며, 그룹 수를 미리 지정해주지 않더라도 최적의 그룹을 자동으로 탐색가능한 점이 있다.
특히 우리의 사례처럼 우리가 찾고자하는 특성을 띄는 그룹(여기서는 target = 0, 파란색 점들)이 변수들 사이에서 어느정도 밀도를 가지고 뭉쳐있다면, DBSCAN을 통해 우리가 원하는 데이터 그룹을 객관적으로 묶어낼 수 있다면, 이에대한 특성을 규명하기도 용이할거라 판단하였다.
* 예로, DBSCAN이 아래의 scatter plot에서 구독 취소(0) 가 더 많이 포함된 그룹 vs 구독 취소(0) 가 거의 포함되지 않는 그룹을 적절히 나눈다면, 수집된 데이터에서 구독 취소가 발생할 확률이 높은 그룹의 유저를 특정해낼 수 있다.

DBSCAN은 scikit learn 라이브러리의 cluster.DBSCAN 모듈을 통해 간단하게 구현할 수 있고, eps, min_samples이라는 두가지의 핵심 하이퍼 파라미터를 가지고 있으므로, 2중 for문을 활용하여 이 두가지 변수에 대해 적절한 하이퍼파라미터를 탐색하였다. (각 하이퍼 파라미터에 대한 자세한 설명은 더보기와 같다)
이 두가지 파라미터는, 클러스터를 형성하는 핵심 포인트 core point의 선정기준으로, epsilon(eps) 는 중심 거리, min_samples 는 core point 가 되기 위한 반경내의 최소 포인트 수이다.
최종 군집은 core point 영역 내에 또다른 core point 가 존재한다면 하나의 클러스터로 뭉쳐지게 되고, 최종적으로 군집 내 포함된 core point와 그 영역 내에있는 border point 가 같은 하나의 클러스터로 배정된다.
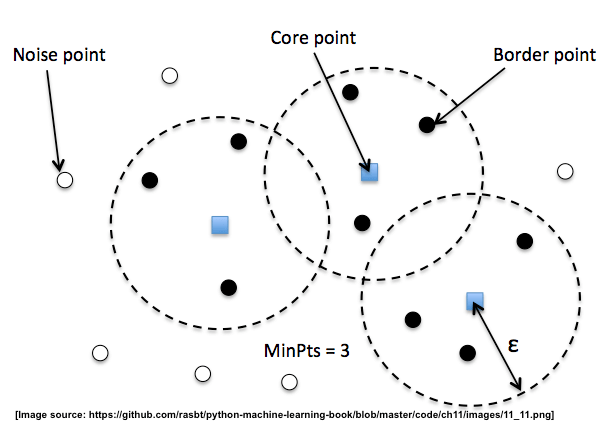
변수 값의 범위와 이상치, 범주형 변수의 척도 수가 상이함을 근거로, Standard scaler를 활용하여 정규화를 진행하였고, 최적 군집 탐색을 위한 하이퍼 파라미터를 탐색하기 위해 epsilon은 1~10, min_samples는 3~10, 총 70가지의 경우의 수를 고려하였다.
유의미한 군집 선정방식으로, scatter plot 를 반복적으로 그려보며 임의로 적절한 하이퍼 파라미터 조합을 선택하였는데, 그 이유는 70가지 조합 중 안정적인 군집 갯수를 유지하고 군집별 분류 데이터 수가 충분히 확보되는 경우가 매우 드물었기 때문이다. 그 중 epsilon = 3, min samples = 3일 때 각 클러스터간 경계가 뚜렷하고 군집 데이터 수가 가장 균형잡힌 모습을 보여 이를 채택하게 되었다.



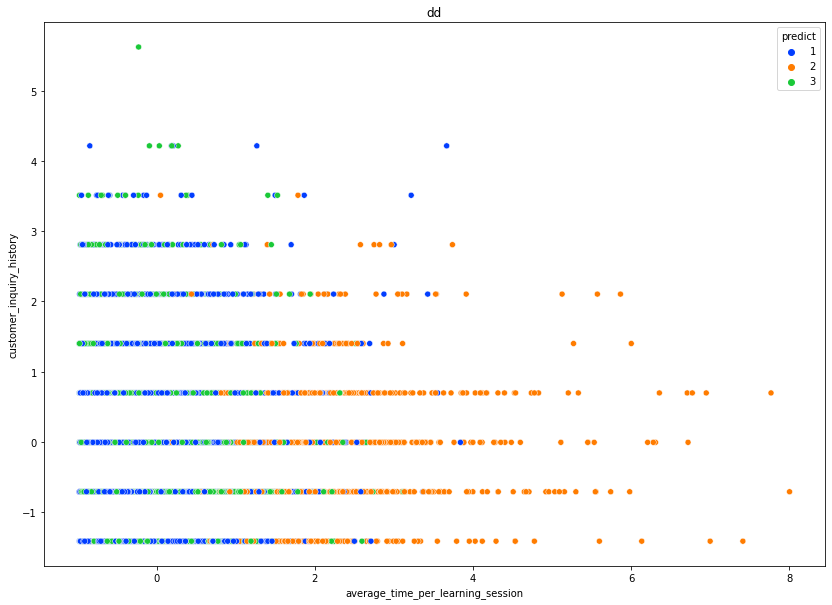
다음으로 DBSCAN의 클러스터 예측 결과를 'predict' column으로 두고, 각 사용자 군집의 데이터 특성 파악을 위해 여러 기술통계량 계산 및 plot을 활용하여 분석을 진행하였다. 이때, '평균 학습 세션 유지 시간', '고객 문의 이력' 이 특히 높은 파란색 그룹(-1) 그룹을 그룹 A, 두 변수에서 모두 일반적인 수치를 보인 주황색 그룹(0) 을 그룹 B 로 두어 비교를 진행하였다. 또한 그룹 비교를 위하어 여러 기술 통계량 및 plot을 활용하여 그룹의 두드러진 특성을 밝히고자 하였다.
이를 통해 알 수 있는 그룹 A, B 의 특성은 다음과 같았다.
- '평균 학습세션 유지시간'이 길고, '고객 문의 이력'이 높으며, '높은 학습 난이도' 를 선호하는 특성을 보인 "군집 A", '학습 세션 중단 수' 역시 비교적 높은 유저가 많은것으로 관측되었다
- 군집 A 의 연장 비율(86%)이, 군집 B의 연장 비율(62%)보다 20%p 이상 높은 수치를 기록했다.
(seaborn plot 의 hue 파라미터가, 범주 -1 을 인식하지 못하는 문제로, 임의로 클러스터 범주를 -1/0 -> 1/0 으로 변경)

1-3. 분석 결론
정리하면, DBSCAN을 통한 군집 분류에서 최종적으로 알 수 있는 점은.
- 평균 학습세션 유지시간이 길거나, 고객 문의 이력이 매우 많거나, 또는 선호 난이도가 높은 특성을 보이는 "그룹 A"의 학습 그룹은 거의 85% 이상 구독을 유지하는 유저층이다. 그러나 반대로, 구독 유지 비율이 상대적으로 낮아 실제 구독 전환 프로모션이 필요한, "그룹 B" 의 경우, 상대적으로 특별한 군집 특성을 가지고 있지 않았다.
- 즉, DBSCAN을 활용하여 분류한 구독 유저 유형분류는, 유의미한 비지니스적 결론에 있어 유의미한 마케팅 대상을 축소하는 것 이상의 의미를 갖지 못했다.
2. 계층적 군집화 (Ward linkage)
2-1. 분석 과정
다음으로, 소비자 유형분석 논문의 분석과정을 참고하며 계층적 군집화 및 군집분석을 진행하였다.
먼저 군집화 방식을 고민하였고, linkage method 를 선택하게 되었다.
우리의 수집 데이터 내에는 여러 연속형 변수와 범주형 변수가 혼합되어 있으며 범주형 변수에서도 단순 이분 변수(1/0) 뿐 아니라 횟수를 나타내는 이산변수들이 포함되어 있기에 이를 고려하여 군집 내 각 변수의 분산을 고려하는 ward linkage 방식을 채택하게 되었다.

실제 데이터에 대해서도, scipy 라이브러리의 dendrogram의 method 인자로 'single', 'median', 'centroid', 'ward' 방식의 linkage을 모두 수행해본 결과 아래의 'ward' 방식에서 아래와 같은 가장 안정적인 dendrogram을 보여주었다.

다음으로 최적의 군집 수를 선정하였다. 군집 수 선정은 아래의 3가지 기준을 자체적으로 두었다.
<선택 기준>
1) dendrogram을 활용한 안정성 판단
2) silhouette score 계산
3) 각 군집간 target에 대한 개별 분류모델 모델링 비교
이 세가지에 대해 조금 더 풀어 설명해보면,
dendrogram은 그룹을 tree 형태로 뭉쳐가는데, 특히 위아래로 가지가 긴 구간은 각 군집을 합치는 기준이 완화되더라도 잘 합쳐지지 않는 안정된 군집들을 의미한다. 즉, 안정적 군집 수 선택을 위해, dendrogram을 참고하여 안정된 구간의 그룹 갯수를 파악하여 선정할 수 있다.
silhouette score는 각 군집화 방식간 성능비교 척도로 사용되는 지표로, 기준이 되는 군집이 얼마나 내부적으로 잘 뭉쳐 있고 다른 군집과 얼마나 잘 구분되는지를 수치화한 지표이다. 일반적으로 모든 군집에 대한 silhouette score를 평균낸 average silhouette score 을 군집 안정화 지표로 활용하게 되는데, 이때, 지표가 1에 가까우면 안정적(clear cut) 군집 분류, 0에 가까우면 약한(weak) 군집분류로 판단한다.
마지막으로, 각 군집간 target에 대한 개별 분류모델 모델링 이후 변수중요도를 비교하는 방식이다. 통상 해석 가능한 모델에서 모델링 후 변수중요도를 계산하는 이유는, target 예측을 위해 어떤 변수가 가장 영향을 끼치는지를 상대적으로 비교하기 위해서이다. 만약 군집화 이후 각 군집마다 개별 모델링을 실시했을 때 만약 변수중요도가 그룹마다 다르게 나타난다면, 이는 곧 각 그룹마다 target(여기서는 구독 연장 여부)에 가장 영향을 미치는 요소가 달라진다는 의미이므로 각 그룹이 서로 이질적임을 역으로 증명할 수 있다.
실제 데이터에 대해서, 군집 수를 2~9로 변겅하며 3가지의 기준 하에 적절한 군집 수를 결정하였다.

<선택 결과>
1) dendrogram 기준으로 2개 ~ 5개의 그룹일 때 가장 안정적인 모습을 보인다.
2) silhouette score를 기준으로, 2개, 3개의 군집일 때 score가 가장 높게 나타났다.
3) 그룹 갯수를 달리하여 비교한 plot에서, 2개, 3개의 군집일 때 가장 군집 간 차이가 뚜렷하게 나타났다.
+) 논문 방식인, target 예측에 대한 유의미한 변수가 군집마다 서로 다른지로 비교 시, 각 군집마다뚜렷한 차이가 관측되지 않아 결과에 반영하지 않았다.
결론 : 최적 군집 갯수로 2개 군집, 3개 군집을 선정.
1) 2개 군집 - 일반적인 그룹 A vs 학습 참여율이 높은 그룹 B
군집 수를 2개로 두었을 때, 상대적으로 '평균 학습세션 유지시간'이 길며, '완료 총 코스 수' 및 '학습 커뮤니티 참여율'이 높고, 'Premium 구독 형태'를 선호하는 그룹 B를 발견할 수 있었다.
그러나 이 두 그룹에 대해서 구독 연장유저의 비율은 각각 그룹 A 64%, 그룹 B 61% 로 차이가 크지 않았으며, 각 군집간 target에 대한 개별 분류모델 모델링 결과 역시 각 변수 중요도에 대한 차이를 보이지 않아 두 그룹간에 구독 연장에 있어 유의미한 차이가 존재한다고 보기 힘들다.


2) 3개 군집 - Basic구독 선호 그룹 A vs Premium 구독 선호 그룹 C vs 구독 연장 그룹 B
군집 수를 3개로 두었을 때,
'Basic 구독 형태', 상대적으로 낮은 '학습 완료 코스 수' 와 '커뮤니티 참여도' 를 보인 그룹 A,
'Premium 구독 형태', 상대적으로 높은 '학습 완료 코스 수' 와 '커뮤니티 참여도' 를 보인 그룹 C,
'평균 학습세션 유지시간'이 길며, 평균 이상의 '커뮤니티 참여도' , 매우 높은 '구독 연장' 비율을 보인 그룹 B
를 탐색할 수 있었다.""
특히 구독 연장 비율 비교에서
그룹 A는 구독 연장 비율이 0.8%
그룹 B는 구독 연장 비율이 99.8%
그룹 C는 구독 연장 비율이 66.4%
로, 그룹별 구독 연장 비율이 눈에 띄게 차이가 났다.

이러한 군집화 결과를 분석 목적에 활용한다면, 특히 구독 연장 비율이 매우 낮은 그룹 A (전체 유저의 약 56%) 만을 대상으로 구독 연장 전환을 위한 프로모션을 진행하더라도 그 효과가 매우 클 것으로 생각된다.
지난 '소비자 유형 분류' 논문 리뷰에서, 소비자 군집의 target 예측 모델링에서의 변수중요도를 기준으로, 그 군집의 우리가 원하는 target 목적 달성을 위한 마케팅 전략을 수립하는데 활용했던 방식을 그대로 차용하여, 우리 문제에서 예측에서 가장 유의미했던 하이퍼파라미터가 튜닝된 xgboost 모델을 그룹 C 데이터를 바탕으로 모델 학습을 진행하였고 이에대한 변수중요도를 아래와 같이 계산하였다.
그 결과, '평균 로그인 유지시간', '최근 학습 성취도', '평균 로그인 시간'이 유의미하게 '구독 연장 여부'(target)에 영향을 끼치는 변수로 판단된다. 즉 구독 연장 유지를 위하여 이 세가지의 변수를 유의미하게 높일 수 있는 프로모션을 진행하여 구독 연장률을 높이는 전략을 취할 수 있다.

2-3. 분석 결론
계층적 군집화 Ward linkage 통한 군집 분류에서 최종적으로 알 수 있는 점은,
- 낮은 학습 참여도, basic 구독 형태를 선호, 구독 연장 비율이 1% 수준의 그룹 A vs 높은 '평균 학습 세션 유지 시간' 을 보유하고 구독 연장 비율이 100%에 가까운그룹 B vs 높은 학습 성취도, Premium 구독 형태 선호, 구독 유지율이 60% 이상인 그룹 C
- 구독 연장률이 현격히 낮은 그룹 A 유저는 전체 구독자 중 약 56%로, 구독 연장률을 높이기 위하여 그룹 A의 특성을 파악하고 맞춤형 연장 전략을 수립하는것이 효율적이다.
- 그룹 A 에 대한 구독 연장 여부에 대한 XGB 모델링 결과, 구독 연장 예측에 가장 영향을 끼치는 변수로 '평균 로그인 유지시간', '최근 학습 성취도', '평균 로그인 시간' 으로 확인되었고, 이 변수 지표를 높일 수 있는 프로모션을 진행하여 구독 연장률을 따라 높이는 전략을 취할 수 있다. (반복적인 접속을 유도할수 있는 동기부여, 접속을 유지할 수 있도록 하는 장치)