part 1 에서는 분석 목적을 정의하였고, part 2 에서는 EDA를 통해 데이터 분포 특성을 파석하였다. part3에서는 본격적으로 모델링을 통해 구독 연장/취소 여부를 예측해보고, 다음 파트에선 더 나아가 나아가 소비자 유형 분석을 통해 각 유저 군집을 나눠보고 군집 특성을 파악해 보고자 했다. (군집 간 서로다른 특성을 이용해 프로모션에 활용.)
0. 개 요
분류 예측을 위해 5개의 모델, 소비자 유형 분류를 위해 2개의 군집화 모델을 활용하였다.
Classification Model : Logistic Regression, Random Forest, XGBoost, DNN, K-NN
Clustering Model : DBscan, Ward Linkage
그 중 XGBoost 하이퍼 파라미터 세팅으로, validation 기준 F1-score : 0.59, public 기준F1-score : 0.48, 21위를 달성했고, 이후 다양한 모델들과 방법론들을 답습하고 새로 적용해보며 다양한 시도를 거쳤다. 또, 비지도학습을 통해 구독 유저를 군집화하여 '학습 세션 평균 시간' 이 높은 유저층 vs 낮은 유저층, '구독 유형'이 Basic인 유저층 vs Premium인 유저층을 분리하여 그 특성을 비교하였다.
구독 연장 여부 예측모델의 결론부터 말하자면 binary classification 문제에 비해 굉장히 분류 성능이 낮은 어려운 문제였다. 그 근거로, 아래는 가장 분류 성능이 좋은 변수 조합과 하이퍼파라미터 세팅으로 3등을 차지한 KNN (k = 1, n_feature = 2) 분류기를 방식을 차용하여 직접 구현하고, 최적 분류 결과를 도식화해본 그래프이다. (validation accuracy : 0.52, f1_score : 0.54 )
최적의 KNN 모델으로, 'average_time_per_learnig session', 'customer_inquery_history' 변수만을 이용한 k=1 의 모델
1. 구독 연장/취소 예측
1-1 Logistic Regression - 분류 실패
target 을 기준으로, target과 각 독립변수 간의 상관계수를 계산하여 정렬하였다. 계산 결과 '평균 학습세션 소요시간 (average_time_per_learning_session)' 을 제외한 모든 변수들이 상관계수 절댓값 0.02 이하 값을 가졌다. 즉, target 예측에 있어 선형 모델의 학습 과정이 매우 힘들 것으로 예상되었다.
target 변수와의 상관계수
Logistic Regression을 진행하기에 앞서 공통적으로
1) scaler로 standard scaler를 활용하였고,
2) sklearn 도큐먼트를 참고하여 panelty, solver, c 등의 하이퍼 파라미터 조합을 탐색하였으며,
3) target class 불균형을 완화하기 위해 under_sampling을 진행하였다.
LR 1)payment _1_month_ago, payment_2_month_ago, payment _3_month_ago 변수는 target 예측에 영향을 줄까?
이러한 검증을 진행한 이유는, 결제 여부가 곧 구독권 구매와 관련있는 변수라고 생각했고, 더 나아가 "특정 시점의 결제가 어떤 목적(그 달의 이벤트 등)에 의해 발생됐다"는 가설을 세웠기 때문이다. 이를 간접적으로나마 검증하기 위해, 세가지 변수의 target에 대한 예측 영향력이 어느정도인지를 LR 모델의 적합 회귀계수 추정값을 기준으로 판단하고자 하였다.
3개 변수 모두 각 월에 대한 결제 여부(1/0) 값을 가지므로 별도의 scaling 없이 모델을 추정하였다. 그러나 추정 결과 회귀계수 값이 매우 작으며, 모든 예측치를 표본수가 많은 1로 예측하는 등, 모델 적합에 실패하였다.
이는 세가지의 변수, 더 나아가 'payment_pattern'이 'target' 예측에 의미가 전혀 없는 변수이거나, 선형 예측 자체가 불가능한 문제임을 암시한다.
추정에 대한 회귀계수 절댓값이 0.05 이하로, 각 변수가 1/0 값을 가지므로 매우 무의미한 변수임
회귀 추정 불가 및 target class 불균형으로 인한 예측실패, 정확도 64%, f1-score 0.34
LR 2) 모든 변수 활용한 LR
payment_pattern등 타 변수와 상관성이 높은 일부 변수를 제외하고, 최대한 많은 변수를 활용하여 target을 예측하였다. 예측 결과, undersampling으로 표본 비율을 동일하게 조정하였음에도 모든 예측값을 구독연장(1)으로 예측하였다. 즉 예측 실패.
이는 역시 모든 변수가 target 예측에 유의미한 변수가 아니였거나, 선형 분리가 불가능하거나, 교차효과 또는 변수간 상관성 때문에 회귀계수 예측이 불가능했음을 보여준다.
역시, 모델 적합에 실패하였다.
LR 3) ViF 계수를 기준으로 한 후진 제거법 활용
LR2 과정에서 많은 하이퍼파라미터 조합에 대해 실험해 봤기에, 이번엔 변수 간 상관성에 의해 적합이 되지 않았다는 가설을 증명하기 위해 다음 두가지의 변수 선택법을 고안하였다.
1) ViF 계산을 통해 가장 높은 다중공선성을 갖는 변수를 순차적으로 제거. (독립변수가 0개가 될 때까지 반복)
2) random 변수를 하나씩 선택하여 순차적으로 제거. (독립변수가 0개가 될 때까지 반복)
그러나 결론적으로, 두가지 방법에서 역시 모든 데이터를 구독 연장(1)으로 예측하며 모두 모델 적합에 실패하였다. 원인을 명확히 밝히긴 힘들지만, 역시 선형분리의 어려움 때문이라는 생각이 들었다.
* 그러나 제출 시 최종 public score는 0.48로, 위의 validation 성능은 train dataset에 과적합된 결과로 생각된다.
XGB의 validation에 대한 Confused matrix
XGB 변수 중요도
1-3 DNN
간단하게 참고 코드를 활용하여 DNN을 구현하였으나, cuda의 문제로 실제로 실행해볼수는 없었다. (무한 로딩, 아마 노트북이다 보니 메모리 문제인듯 하다.)
그러나, DNN 구조상 초반 노드에서 feature mixing을 진행하다보니 중요 변수들을 추출 및 재생산하여 사용할 수 있어 비선형 문제인 다음과 같은 문제를 잘 풀수 있다고 생각하고, 실제 public 1위 역시 아래의 코드를 조금 수정한 방식 ( BCELoss→ MLELoss 등) 으로 문제를 해결하였다.
public 2등, 3등의 방법이 모두 KNN 이었던 점, 그리고 소비자 유형 분류를 위한 여러 clustering 모델을 활용하면서, 생각보다 target 분포와 유사한 cluster를 탐색한 모형이 많았고, 이를 답습 및 여러가지 방식으로 시도하며 classification에 활용하여 성능을 살펴보았다.
공통적 방법론으로
1) distance 개념을 활용하므로 scaling은 필수, 범주형 변수 처리를 어떻게 할지 고민할 필요가 있음.
2) 계산 효율성, 모델 성능을 위해 hyper parameter 뿐 아니라, 어떤 변수를 사용할 것인지에 대한 고민 필요.
KNN)
개인 public 점수를 올리기 위해 knn을 사용하긴 했지만, 3등 코드를 보면서 특히 충격적이었던 점은 모든 변수를 KNN 학습에 사용하지 않았던 점이었다. 실제 3등 코드는, target class가 그나마 잘 구분되는 단 두개의 변수, 'average time per learnig session', 'customer inquery history' 만을 사용했으며 class를 구분하기 위한 이웃 수 k는 단 1로 두었다.
또한 계층적 clustering을 진행해보면서, 사용된 두 변수가 dendrogram 등 계층적 군집화에서 군집간 distance가 가장 잘 구분되는 최적의 변수들의 조합중 하나임을 나중에 알게 되었다.
학습된 최적의 KNN 모델의 분류영역과 True validation class
DBscan )
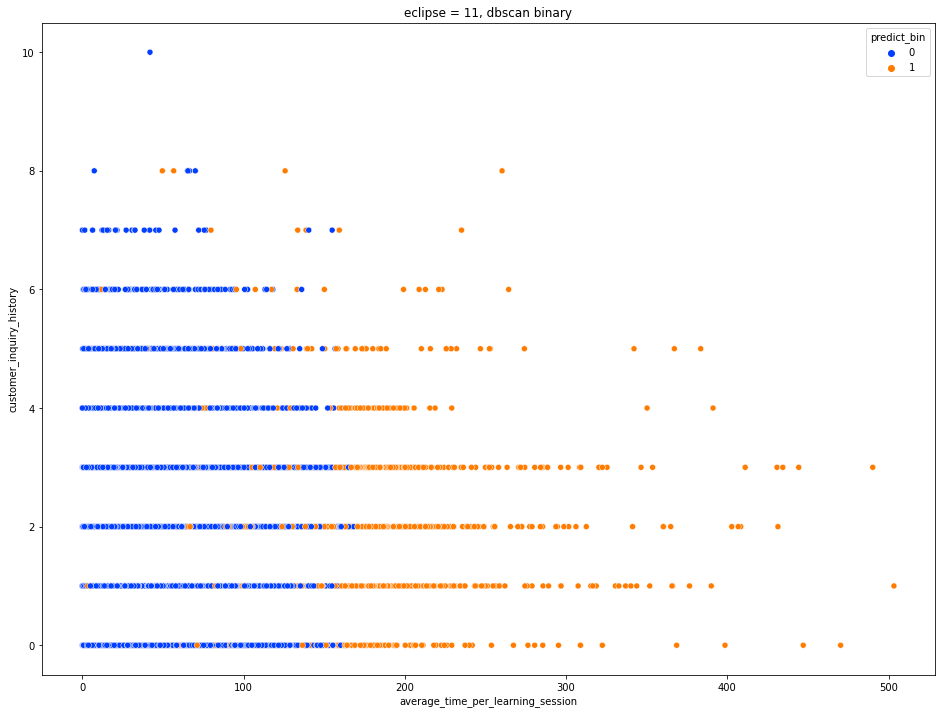
이상치 탐지 및 고객 세분화 목적으로 DBscan을 활용하여 하아퍼파라미터 eclipse, min_pts 를 조정하던 중, 군집이 잘 이루어진 파라미터에서 target 의 구독취소 (0) 데이터 군집과 유사한 군집을 발견하여, 이를 classification 기준으로 삼으면 어떨까 라는 생각에 간단하게 classification에 활용해보았다. validation 데이터를 train 된 DBscan 모델에 동일한 방식으로 분류한 결과, accuracy 0.49, f1-score 가 0.46정도로, 생각보다 좋은 성능을 얻었으며 이를통해 target class들(특히 구독 취소 그룹)이 고차원 공간에서 밀도있게 모여있음을 의미한다고 해석 가능하다.
탐색한 최적의 min_points에서의, eclips 파라미터 조정 결과DBscan(eps=11) 에서의 group 0 vs 나머지 groups을 각각 target prediction으로 배정하여 binary classification 문제로 변경
최종적으로, true_y = prediction 인 경우 2(red), 틀렸을 때, true_y가 1이면 1(coral), true_y 가 0이면 0(blue) 로 지정하여 시각화.
2. 결론
본 part는 사용자 유저 정보 14개를 이용하여 구독 연장 및 취소 여부 예측을 목표로 모델링을 시도하였고 5개 정도의
classification model 및 방법론을 활용하였다. 다수의 이상치 및 각 변수들의 target class 별 구분이 매우 어려운 문제였기에, 비선형 모델, tree 기반 모델, distance 기반 군집 모델에서 비교적 좋은 모델들이 많이 나타났다.
Dacon competition 목적에 맞게 가장 성능이 좋은 모델을 탐색하려고 노력하기도 하였지만, 최대한 다양한 방법론들을 공부하며 문제에 적용해보고, 인사이트가 떠오를 때 마다 데이터를 기반으로 이러한 가설들을 증명해보고 결과를 해석해보는 관점에서 좋은 공부가 되었다고 생각한다.