[Dacon] "학습 플랫폼 이용자 구독 갱신 예측" .part2 (EDA)
part 1에서 "학습 플랫폼 구독 취소 예측 유저를 예측하여 구독을 연장하도록 프로모션을 진행하고, 이를통해 구독 수익을 증대시키자" 라는 목표를 컨셉으로 기대수익을 정의하였고, part 2에서는 본격적인 플랫폼 구독 갱신 유저 예측을 위해 데이터를 살펴보았다.
데이터 수집 경로 : [Dacon] "학습 플랫폼 이용자 구독 갱신 예측 해커톤"
0. 분석결과 요약
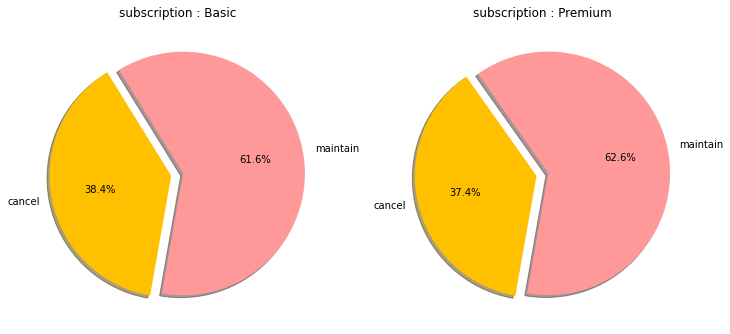
- 구독 연장률은 62%, "구독 연장유저 vs 구독 취소유저" 간의 분포차이는 '평균 학습 세션 시간' 을 제외한 거의 모든 변수에서 차이가 없었다.
- 독립변수 대부분 균일분포 또는 정규분포에 가까웠고, 일부 변수에서 분포의 치우침, 매우 큰 이상치가 괸측되었다.
- '3개월간 결제 패턴', '특정 월에 결제를 진행한 유저' 간 통계적 차이가 존재하는지 검증하기 위해 f-oneway(일원 분산 분석)을 진행, '구독 유형(Basic/Premium)'에서 유의미한 통계적 차이가 발생하였음.
- 독립변수간 일부 상관관계가 존재했다.
결론 :
- 주어진 변수로부터의 구독 연장유저와 취소유저간 선형 구분이 매우 힘들것으로 예상된다.
- 이상치 및 변수의 치우침을 처리하기 위하여 Log1p 변환 및 트리기반 모델 활용을 고려할 필요가 있다.
- 독립변수간 상관성 및 교차효과 처리를 위해 변수선택/교차효과 변수 추가/차원축소/PCA/feature mixing 등을 고려할 수 있다.
1. 분석과정
1-1. 변수 특성 파악 및 분포 파악
데이터셋은 특정 학습 플랫폼의 총 10000여개의 독립적인 유저 데이터(rows), 14개의 독립변수, 1개의 타겟변수(구독 연장 여부)로 구성되어 있다.

참고로 'payment pattern' 변수는 최근 3개월간 결제 유무 패턴을 총 8가지로 분류한 변수이며 본인은 이를 조금 더 자세히 살펴보기 위하여, '1 month ago pament', '2 month ago pament ', '3 month ago pament' 로 분리하여 비교해보기로 하였다.
Pandas 라이브러리의 describe 매서드를 통해 평균값 중앙값 비교, 최댓값, 최솟값, 분위수를 기준으로 분포의 치우침을 수치적으로 확인하였으며, histogram, dist plot, Box plot을 활용하여 분포의 치우침 및 이상치여부를 시각적으로 판단하였다.

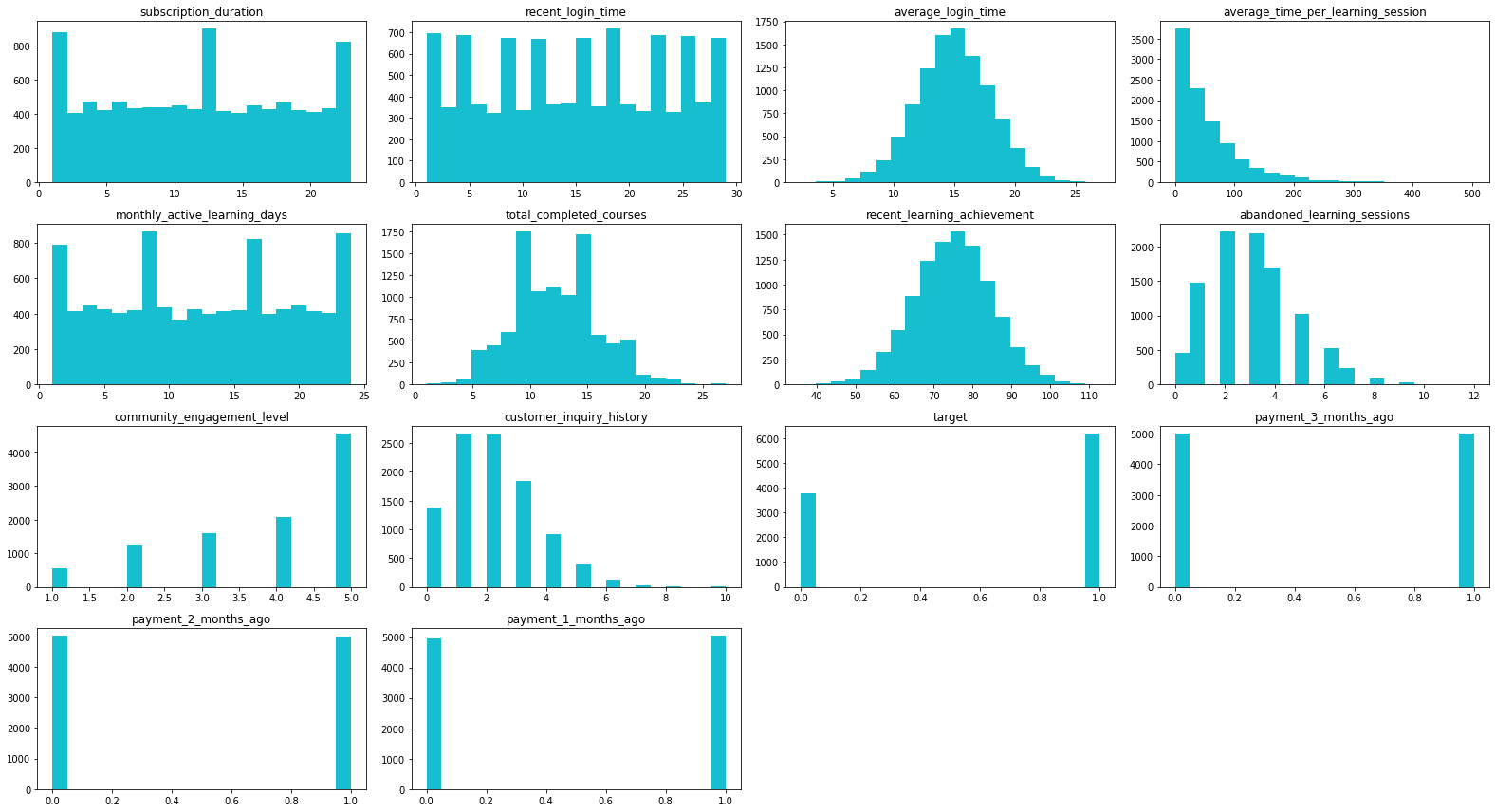

분석 결과 :
- '학습세션 평균 소요시간' 이 왼쪽으로 치우친 분포를 취하며 최대값 503분이라는 이상치 존재, '중단된 학습 세션 수' 변수 역시 평균 및 중앙값 3과 크게 차이나는 최대값 12를 가짐.
- '학습세션 평균 소요시간' , '중단된 학습 세션 수' , '커뮤니티 참여도' 변수의 분포 치우침은 log1p 을 통해 유의미하게 개선되었음.
1-2. 구독 연장유저 vs 구독 취소유저간 분포 차이
구독 연장 유저와 구독 취소 유저간 차이 비교를 위하여 counterplot, histogram, boxplot, kdeplot, pairplot 을 활용하여 비교하였다. 대부분의 변수에서 두 유저층 간의 차이는 거의 없었으나, '평균 학습세션 시간' 등 일부 변수에서 분포차이를 관측할 수 있었다.
분석결과 :
- 모든 변수에서 구독 연장 유저와 취소 유저간 유의미한 차이를 확인하기 힘들었다.
- 유의미한 분포차이를 갖는 변수는 '학습세션 평균 소요시간' 으로, 소요시간이 200분 이상의 유저는 모두 구독을 연장하였다.



1-3. 변수간 상관성 분석
pairplot 을 통해 구독 연장/취소 유저의 각 변수별 분포차이, 두 독립변수 축 내에서의 분포, 상관계수(회귀선 기울기) 등을 간단하게 확인할 수 있었다.
특히 '학습 완료 세션 수' 변수는 '구독 형태', '선호 난이도', '학습 커뮤니티 참여율' 과 큰 상관성이 있는것으로 파악되므로 이를 통해 유의미한 인사이트를 찾는다면, 학습 완료를 많이 한 유저일수록 구독 형태가 Premium, 높은 난이도를 선호, 높은 커뮤니티를 참여하는 경향을 보인다는 인사이트를 얻을 수 있다.
추가적으로 두 변수 간 추정 회귀선이 구독 연장/취소 유저에 있어 유의미한 차이(두 회귀선 사이의 간격이 크거나 음의 상관과 양의상관 교차)가 발생한 일부 변수들이 존재하기도 하는데 이는 교차효과나 외생변수의 영향일 수 있고 이를 확인하기 위해 추가적인 분석이 필요해보인다.
분석 결과 :
- '학습 완료 세션 수' <-> '구독 형태', '선호 난이도', '학습 커뮤니티 참여율' 간의 강한 상관관계가 존재.
- 일부 변수조합에 있어 교차효과나 외생변수가 존재할 수 있음.

1-4. 결제 패턴별 분포차이
payment pattern 즉 결제 패턴 컬럼은 최근 3개월간 결제 유무를 패턴화하여 0-7까지의 총 8개의 범주로 이루어져 있으며, 자세히 보면 아래와 같다.
| 범주 | 3달 전 결제 유무 | 2달 전 결제 유무 | 1달 전 결제 유무 |
| 7 | O | O | O |
| 6 | O | O | X |
| 5 | O | X | O |
| 4 | O | X | X |
| 3 | X | O | O |
| 2 | X | O | X |
| 1 | X | X | O |
| 0 | X | X | X |
이때 나는 다음과 같은 생각을 했다.
"만약 구독권 구매 역시 결제에 포함된다면, 이는 곧 결제 갱신 주기로 볼 수 있지 않을까?"
이어 아래와 같은 가설을 생각하게 되었다.
- 3개월간 결제 이력이 없지만 구독이 유지되고 있는 유저(0)는 장기 구독 유저, 매달 결제가 이어진 유저(7)는 짧은 구독권을 자주 구매하는 유저일까?
- 또, 특정 월에 구매를 진행한 유저는 그 달 특별한 결제 이유(프로모션, 할인혜택 등의 충동결제)가 있었을까?
이러한 가설들을 검증하기 위해 아래와 같은 다양한 분석들을 진행하였다.
- payment pattern이 서로 다른 유저들(0-7 범주 각각)은 각 변수에 대해 유의미한 행동차이가 존재하는지 검증.
- 3개월간 결제 이력이 있는 유저(1-7) vs 결제를 하지 않은 유저(0) 의 차이가 존재하는지 검증.
- 3개월간 결제 이력이 없는 유저 vs 1달 전 결제 유저 vs 2달 전 결제 유저 vs 3달 전 결제 유저 간의 차이 검증.
검증 방법으로는 ANOVA oneway 즉 일원분산분석을 활용하여 모든 변수에 대해 검증 대상들의 평균값이 유의미하게 차이나는지 분석하였으며, 이 외에도 보조적으로 kdeplot, box plot, violin plot 을 활용하여 시각적으로 분포차이를 확인하였다.
from scipy.stats import f_oneway, kruskal
# f_oneway 검정 - 다중 분포 차이 검정(모두 동일 vs 하나라도 다름) (https://rfriend.tistory.com/638)
# kruskal-wallis 검정 - 비모수적 다중 분포차이 검정
for variable in df_i.columns.difference(['payment_pattern']):
anova_result = f_oneway(*[df_i[variable][df['payment_pattern'] == pattern] for pattern in df_i['payment_pattern'].unique()]) # *[] : list unpack 기능 수행
# kruskal_result = kruskal(*[df[variable][df['payment_pattern'] == category] for category in df['payment_pattern'].unique()])
print(f"ANOVA for {variable}: F-statistic={anova_result.statistic}, p-value={anova_result.pvalue}")
그 결과, 1-3 가설 모두에서, 유의수준 0.05 내에서 유일하게 subscription type에서 payment_pattern간 유의미한 차이가 발생했는데, plot을 활용해 관측한 결과 공통적으로 3달 전 또는 장기간 결제를 진행하지 않았던 범주 0, 4, 5, 6, 7번의 경우 상대적으로 Basic 구독 형태가 많았고, 최근 결제를 진행했던 1, 2, 3번 범주의 경우 Premium의 구독 비율이 상대적으로 높게 나타났다.
이는 가설과 같이 특정 월의 구독권 판매가 어떠한 프로모션 또는 특별한 시간적 요인에 의해 영향을 받았는지 고민해 볼 수 있는 사안이다.

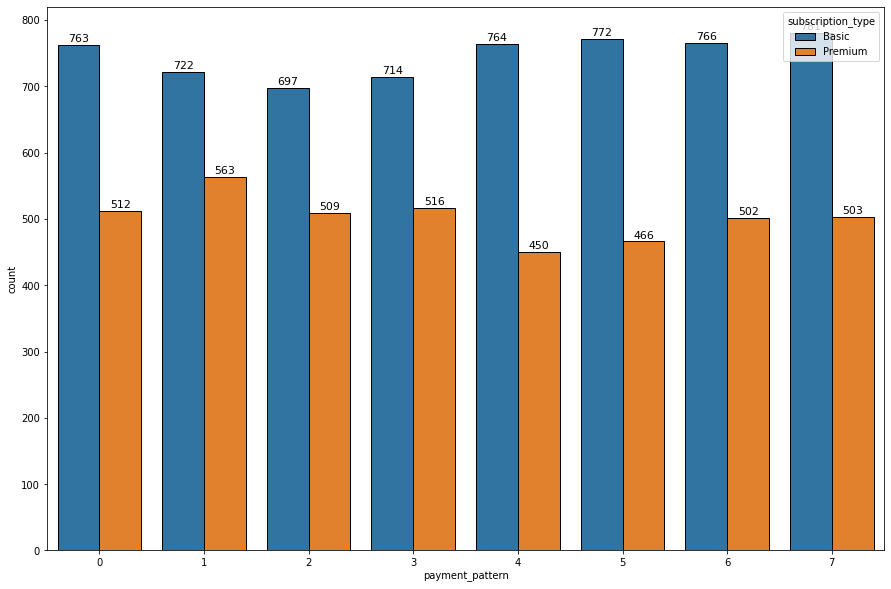
분석결과 :
- '최근 3개월간 결제 패턴'이 다른 유저들은 '구독 유형'에 있어 Anova 분석 유의수준 0.05 내에서 유의미한 차이가 있음을 검증하였다.
2. 결론
분석 결론은 0번과 같고, 본격적으로 내가 해보고싶은 분석을 진행해보며 느낀바를 간단하게 써보려고 한다.
기존의 딥러닝 및 모델링에서의 EDA는 모델 입력 및 예측성능 향상을 위한 목적이 컸다면, 이번 EDA에서는 데이터에 대해 깊게 고민해보며 유저특성을 파악하기 위해 다양한 분석법을 활용하여 가설을 세우고 검증을 진행하였다.
사용자 유저 특징을 분석하며 특별한 유저층의 특징을 몇가지 발견하였고, 차후 모델링에서는 이러한 특성을 반영할 수 있는 이상치 데이터 분석, 요인분석, 군집화, 차원축소등을 이용해 유저를 디테일하게 이해하고 새로운 인사이트를 추출하거나 이를 통해 성능을 높이는 등의 시도를 해보고 싶다.
추가적으로 분석 과정의 설계나 시각화 부분을 앞으로는 체계화하고 싶다. 현재는 분석방법이라던지 시각화 코드들을 즉석에서 제작하고 활용하였으나, 각 분석 및 검증과정에 있어 체계가 부족하다고 생각이 든다. 코드를 따로 정리해둔다던지
분석/시각화 과정을 모듈화해두고 활용할 필요가 있어보인다.