[고객 분석법2] 생존분석/RFM/cohort/고객생애가치/장바구니 분석/추천시스템
업 분석 사례 정리
0. 공부계기
본 내용은 [DACON] "이커머스 고객 세분화 분석 아이디어" 에 참여하여 공부하며 실제 프로젝트에 적용, 또는, 적용을 위해 공부해온 내용을 정리하고자 작성하게 되었습니다. (2025.01 수정)
다루게 될 내용은 아래와 같습니다.
또한 앞으로 자주 활용될 비지니스 용어 정리를 해두는 것이 이해에 도움이 될 것 같아 아래와 같이 정리해두겠습니다.
- CRM - Customer Relationship Management
- 고객 관계 관리 마케팅, 즉 고객 획득보다 기존 고객을 관리하는데 집중하는 방식. (리텐션, 객단가 향상, vip 관리)
- DAU - Daily Active Users
- 일일 앱을 사용하는 순 유저 수
- MAU - Monthly Active Users
- 월별 앱을 사용하는 순 유저 수
- ARPU - average revenue per user
- 사용자 당 평균 수익
- ARPPU - average revenue per playing user
- 유료 사용자(구매자) 당 평균 수익
- LTV - customer Lifetime Value
- 각 유저가 해당 서비스 내에서 창출하는 총 매출액.
1. 고객 생존 분석
(본 내용은 'datarian' 의 '유저 이탈률 계산' 시리즈, 타 생존분석 블로그, 곽기영 교수님의 유튜브 등을 참고하였습니다.)
1-1. 생존 분석이란?
생존분석의 정의는 "어떠한 현상이 발생하기까지 걸리는 시간" 에 대한 분석을 의미합니다.
여기서 현상(=event)이란 우리가 어떠한 조취를 취하고자 할 때 최종적으로 변화시키고자 하는 목적이라고 볼 수 있고, 의료계에서는 특정 치료에 따른 환자의 생존 또는 사망, 고객 분석에서는 유저의 잔존 또는 이탈이 곧 현상 이라고 볼 수 있습니다.
정리해보면, 고객 생존분석은 곧 '유저가 이탈할때 까지의 걸리는 시간' 을 예측하는 것이고, 이는 우리 서비스의 라이프타임을 간단하게 진단해보는 분석 기법 정도로 이해해볼 수 있습니다.
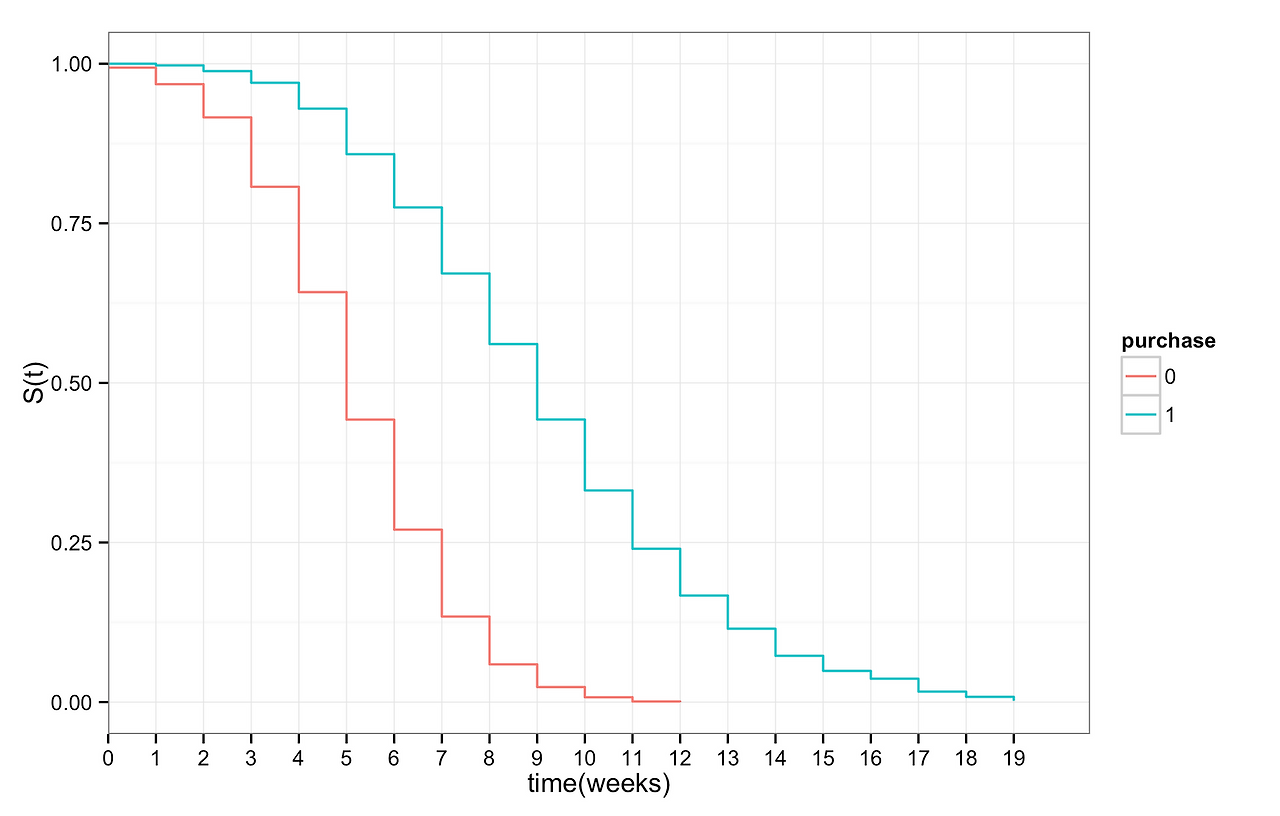
이를 통해, 간단하게 아래 세가지의 분석이 가능합니다.
1) 유저 LTV 예측 - 개별 고객이 서비스 내에 창출하는 총 매출액(LTV)을 다음과 같이 계산 = 월 평균 소비액 * 생존 기간
2) 그룹간 생존률 비교 - 특정 활동을 경험한 유저와 그렇지 않은 유저간 서비스 생존률에 차이가 있는지 비교
3) 서비스 리텐션 파악 - 과거와 현재의 고객 생존시간 차이를 통해, 해당 서비스의 라이프타임의 변화가 있는지 진단
1-2. 생존 분석 예시
(이 부분은 생존분석에 대한 기본 이해를 위한 예시입니다. 바쁘신분은 스킵하셔도 좋습니다.)
생존분석 자체가 의료 통계학에서 등장한 개념이다보니, 가져온 자료가 대부분 '치료에 따른 환자의 사망 여부(생존률)' 을 기준으로 맞춰져 있습니다. 따라서, 고객 생존분석을 목적으로 하시는 분들은 '사망 = 이탈' 로 이해해주시면 되겠습니다.
생존 분석은 필수적으로 '관찰 대상(patient_id)', '이벤트 상태(survived)', '이벤트 시점(timestamp)' 데이터가 포함되어야 합니다. 당연하겠지만, 해당 데이터가 존재해야 실험 경과 시간에 따른 객관적인 사망률(또는 이탈률)을 측정할 수 있기 때문입니다.
또한 모든 실험이 동일한 시점에 동시에 시작한다면, 일반적인 경우에는 아래와 같이 각 환자마다 실험 시작시점이 다른 경우가 훨씬 많습니다.
(예시)
- 암 환자 대상 신약 실험의 생존률 실험은, 환자의 병원 방문 시점을 기준으로 개별 시행되었다. => 환자마다 방문 시점이 다름.
- 특정 서비스 개편 이후 유저의 서비스 활용 시간에 따른 이탈률 실험은, 유저가 개편 이후 첫 방문한 시점부터 측정되었다.
=> 유저마다 방문 시점이 다름.
본격적으로 실험 예를 보겠습니다.
아래는 9년동안 시행된 '대장암 신약 치료제 임상실험'의 생존분석 자료입니다.
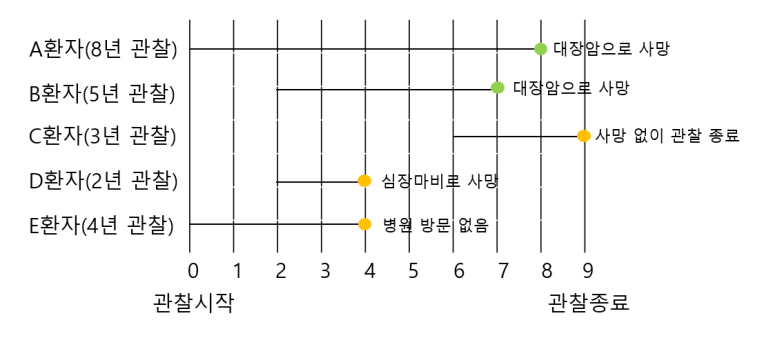
위의 예시 사례를 먼저 간단하게 해석해보면 아래와 같습니다.
- 실험 기간은 9년이며, 각 환자별 실험 참여시점이 서로 다르다.
- 환자 상태(=event) 는 '사망', '절단' 두 가지로 존재한다. 실험기간 내 대장암으로 사망한 경우 '사망', 실험 종료까지 생존했거나 실험 과정에서 다른 원인으로 상태를 알 수 없는 경우(이탈 또는 타 원인으로 사망시) '절단' 상태로 기록한다.
- 연구 시작 7년 만에 첫 사망자(B)가 발생했으며, 실험 이후 총 5명의 조사 환자중 1명 생존, 2명 사망 , 2명 절단으로, 해당 조사 내 생존율은 1/3 = 0.33 이다.
몇몇 분들은 '...아니.. 절단은 뭔데?? 저건 왜 설명도 안해주고 계산에서 빼는거야?' 라고 의문을 가지실 수도 있겠습니다.
절단 데이터란, 조사기간 동안 우리가 설정한 사건(=event)이 발생하지 않고 실험이 종료된 데이터들입니다.
우리가 설정한 사건이 '환자의 사망'인 경우, 조사기간 동안 생존해 있던 고객들은 사망이라는 이벤트가 발생하지 않은 상태이므로 절단입니다. 또한, 이벤트 기간동안, 환자가 더이상 내원하지 않아 생존 여부를 알 수 없는 경우도 절단입니다.
특히, 조사기간 내 환자의 상태를 알 수 없는 절단의 경우, 생존율 해석에서 제거되는데, 이는 흔히 데이터 수집과정에서 수집되는 불완전한 데이터정도로 생각해주시면 되겠습니다.
1-3. 생존 분석 함수 계산
본격적으로 생존분석에 대해 공부해 보겠습니다.
생존분석은, 시간 경과에 따른 고객 생존/이탈 확률을 계산하는 과정입니다.
우리는 특정 실험 대상이, 조취(=가입) 이후 경과 시간(t)에 따른 사건 발생확률을 수치화하는것을 의미합니다.
즉 위와같이, 실험에 참여한 시점이 서로 다르더라도 상관없이, 실험 참여 t 시간 이후까지의 고객생존확률을 계산하는것입니다.
일반적으로 t 시간 이후까지 고객이 생존할 확률은 다음과 같은 확률함수식으로 표현할 수 있습니다.
- 생존함수(Survival Function, S(t)) : 대상이 특정 시간 t 보다 더 오래 생존할 확률
$$ S(t)=Pr(T>t) $$
이를 확률 밀도 함수로 생각해보면, 특정 시점에서의 생존 확률도 계산할 수 있습니다. 이를 위험함수(h(t)) 라고 해보겠습니다.
- 위험함수(hazard function, h(t)): 특정 시점 t 에서 생존해있을 확률.
ex) 유저가 회원가입 8개월(t)이 되는 시점에 생존(잔존)할 확률은? h(t=8) 을 대입했을 때 나오는 값.

그리고 당연히, 참여 이후 특정 기간까지 생존해 있을 확률도 구할 수 있어야겠죠. 이 확률을 위험함수의 적분값인 누적 위험함수라 합니다.
- 누적위험함수(cumulative hazard function, H(t)): 특정 시점 t 까지 생존해있을 확률.
ex) 유저가 회원가입 이후 8개월(t)까지 생존(잔존)할 확률은? H(t=8) 을 대입했을 때 나오는 값.
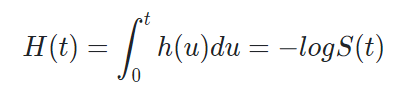
1-4. 생존 함수 모델링 기법 - Kaplan-Meier analysis
아니, 그래서 그 '생존확률' 이란건 어떻게 계산하는건데?
이를 가장 간단하게 계산할 수 있는 모델인 Kaplan-Meier estimation을 알아보겠습니다.
해당 방식은, 정말 말그대로 해당 시점에 생존자 수를 눈으로 셀 수만 있는 수준이라면 굉장히 이해하기 쉽습니다.
(해당 내용은 youtube '곽기영'님 채널의, R로 배우는 통계분석 내용을 참고하였습니다.)

식이 언뜻 복잡해 보일 순 있지만, 이해하면 매우 간단합니다.
먼저, 생존 시간을 구간 단위로 쪼갠 이후(월 or 년 단위), 각 구간별 생존확률을 독립적으로 계산해서 원하는 기간만큼 곱해주면 됩니다. 예를들어, 우리 서비스의 가입 3개월 이후까지 고객이 생존할 확률을 계산하고자 한다고 가정하면, 아래와 같이 풀기만 하면 됩니다.
3개월 후 고객의 생존률(S(t)) = (0~1개월차 생존률) X (1~2개월차 생존률) X (2~3개월차 생존률)
이때, '3개월 후 고객 생존률' 은 누적생존비율(S(t)), '0~1개월 사이 생존률' 등 은 각각 구간 생존율이라고 표현합니다.
아래는, 실제 의료 실험 데이터를 예시로 Kaplan-Meier estimation 를 추정하는 디테일한 과정입니다.
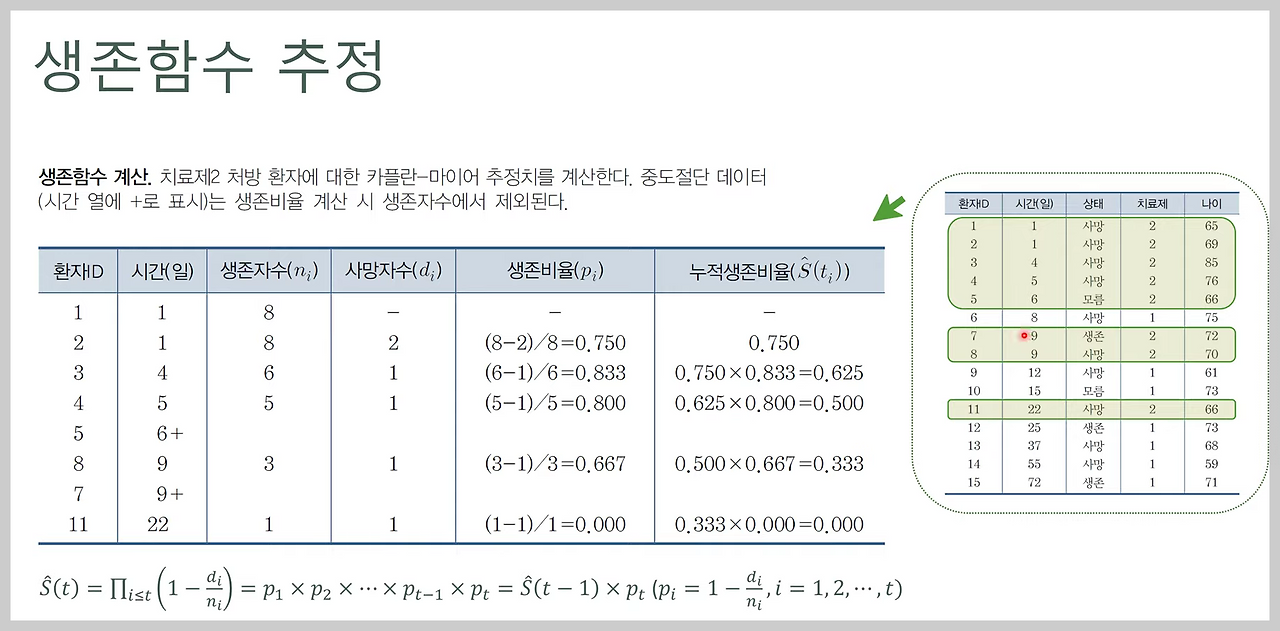
해당 표와 같이 해당 시간대의 구간생존률(p_i) 을 {해당 시점의 생존자 수 - 사망자 수} / {해당 시점의 생존자수} 로 나타낼 수 있습니다.
이때, 예시 내의 상태 '모름'과 같이, 실험 대상이 실험 중간에 이탈하여 처치 결과를 알 수 없는 경우가 발생할수도 있습니다. 이때는, 해당 실험 대상이 확실하게 생존해 있는 시점까지만 '생존자 수'에 포함시키고 이탈한 이후에는 생존자 수에서 빼서 계산하시면 됩니다.
이런식으로 각 시간 구간별로 구간생존률(= 생존비율, p_i) 가 구해지면, 특정 시점 t 까지의 생존률은 누적생존비율(S(t))는 t 시점까지의 구간생존률의 곱으로 계산할 수 있습니다. 그리고, 이를 아래와 같이 시간에 따른 생존률 그래프로도 표현할 수 있습니다.

이러한 추정법은, 특정 서비스 전체의 유저 생존 기간을 파악하거나 또는 각 집단간 생존기간 차이를 비교하는데 간단하게 활용할 수 있습니다.
그러나, 단순히 우리가 샘플로 뽑은 집단 전체의 생존/이탈을 시간별로 잘라서 단순 측정한 방식이므로, 해당 유저 또는 환자가 어떤 특성을 가지고 있는지는 전혀 고려되지 않았습니다. (각 개인이 어떤 배경의 고객들인지, 얼마나 활동성있는 고객들인지에 관계없이 시간에 따른 평균 이탈률만을 계산함)
그렇기에 이를 보완한, Cox proportional hazards model 이나 비선형 기저함수 추정이 가능한 DeepSurv 등의 딥러닝 모델들도 있기때문에 좀 더 정확한 분석이 필요하다면 이러한 방법들을 활용하는 방식도 고려해볼 수 있습니다.
2. RFM 분석
2-1. RFM 분석이란?
CRM 마케팅은 고객과의 관계를 효과적으로 관리하고 각 고객에게 맞춤형 메시지를 제공하여 구매를 유도하는 데 초점을 맞춥니다. 예를 들어, 특정 고객에게 할인 쿠폰을 제공하거나, 생일 축하 메시지와 함께 특별 혜택을 제공하는 사례가 이에 해당합니다.
이러한 CRM 마케팅에서 중요한 점은 고객을 얼마나 잘 이해하고 있는지, 그리고 고객이 어떤 조건에서 구매로 이어지는지를 파악하는 것입니다. 특히, 고객의 행동을 세분화하여 이를 기반으로 할인 문자, 카카오톡 메시지, 고객 등급 혜택 등을 제공하면 더욱 효과적인 반응을 이끌어낼 수 있습니다.
RFM 세분화는 고객 세분화 기법 중에서도, 각 사용자를 얼마나 최근(Recency), 얼마나 자주(Frequency), 얼마나 많은 금액을 지출(Monetary)했는지 3가지 관점에서 이해하고 세분화하여 이해하는 기법입니다.
아래 예시를 보겠습니다.
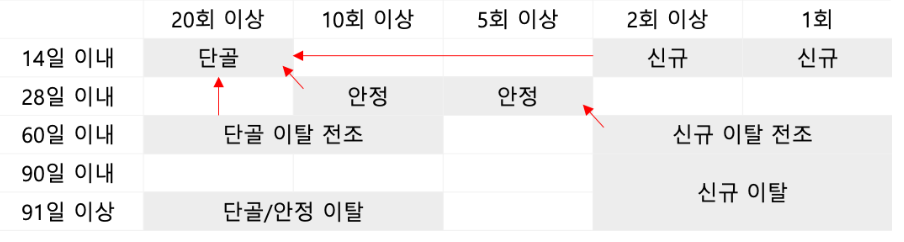
예를 들어, 분석하고자 하는 서비스가 이커머스(온라인 쇼핑몰)이라고 한다면, 오늘 가입한 신규 고객을 바로 충성고객으로 만들겠다는 건 허무맹랑한 전략일 수 있습니다.
위와같이, 고객들이 최근(R), 얼마나 자주(F) (+ 평균적으로 얼마나 지출하는지(M)) 들어왔는지를 기준으로 고객을 신규, 안정, 단골 고객으로 사전 세분화하고, 각 고객별로 서비스 이용 빈도와 충성도에 따라 단계적인 충성 전략을 취하고자 하는것이 RFM 분석의 궁극적인 목표입니다.
이때 주의할 점은, 고객을 분류하는 RFM 기준은 각 서비스에 맞게 설정해야 합니다. 온라인 상에 공유된 여러 RFM 프레임워크를 그대로 따르는것이 아니라, 서비스에 맞게 각각 우리 서비스의 R, F, M 의 기준은 무엇인지, 충성고객이란 누구인지, 이탈고객이란 무엇인지를 자체적으로 정의하고, 그에맞는 액션을 취하는 것이 중요합니다.
2-2. RFM 분석 방법
RFM 분석은 각 고객의 거래 히스토리 데이터 내의 {고객 고유 ID}, {거래 날짜}, {거래 금액} 만으로 간단하게 적용해볼 수 있는 분석 기법입니다.
예를들어, 이커머스 거래 로그데이터가 아래와 같이 저장되어있다고 가정하겠습니다.
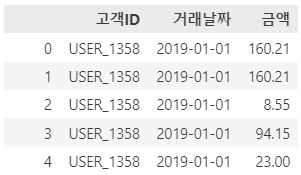
이를 각 유저별로, '가장 최근 구매일(또는 접속일)', '총 구매 횟수', '총 구매 금액'을 중심으로 집계해줍니다.
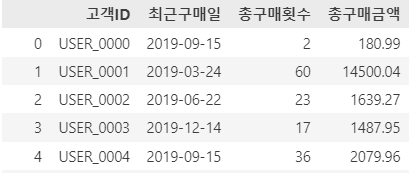
이제 이를 기준으로, 서비스 특성에 맞게 고객 세분화 기준을 세워 정리해주시면 됩니다.
예를들어, 가장 먼저 아래와 같이 사용자 분류 기준을 비지니스 관점에 맞게 세워볼 수 있습니다.


또는 아래의 프레임워크와 같이, RFM 으로 분류된 고객들의 특성별로 묶어내어, 고객 가치별로 세분화 한 이후 이를 시각화하여 표현할수도 있습니다.
이때 각 군집마다, 어떤 고객 특성(RFM 평균값)을 가지고 있는지, 해당 군집에 얼마나 많은 고객들이 속해있는지를 집계하여, 해당고객층이 얼마나 가치있는지, 해당 고객들을 타겟으로 액션을 취했을때 얼마나 효과가 있을지를 예상할 수 있도록 하는것이 중요합니다.

2-3. RFM 활용 방안
RFM 방법대로 따라해봤는데 이제 뭘 하면 되는거죠?
사실, RFM은 고객을 간편하게 고객 가치, 고객 활동성을 중심으로 가장 간단하게 적용해볼 수 있는 세분화 기법이지,
무작정 RFM 분석을 진행했다고 해서 달라지는 건 없습니다.
중요한것은, RFM으로 세분화한 고객들이 어떤 특성이 있으니 이것을 어떻게 활용하겠다는 '액션'이 가장 중요합니다.
그렇기에, RFM 을 우리 서비스에 맞게 어떤 기준으로 세분화할 것이며 어떻게 활용할 것인지, 분석 설계단계가 가장 중요합니다.
다만, RFM 분석 기법에 대해 조사한 내용 중 참고할 만한 아이디어들을 정리해 두겠습니다.
<RFM 정리>
- RFM 분석은 서비스 내 구매 유저를 대상으로 간편하게 분류해볼 수 있는 가장 대표적 아이디어이다.
- 분석 목적에서 출발하여, RFM 의 세부 기준을 세워야 한다.
- 우리 서비스가 집중해야하는 고객은 누구인가?
- 우리 서비스에서 특별히 충성도가 높은 고객들이 찾는 상품은 무엇일까?
- 우리 서비스를 이탈한 고객과 이탈할 위험성이 높은 고객들은 누구인가?
- 우리 서비스의 핵심 매출을 담당하는 고객들은 누구인가 (고래 고객, 파레토 법칙) ?
- 매출 증가/감소 시 어떤 고객층의 유입 또는 이탈이 원인인가?
- 꼭, R, F, M 을 고집해야하는 것은 아니며, 제품 및 서비스 성격을 고려해야 한다.
- 도메인에 따라 RFD (Duration : ott 영상 시청 시간), RFML (Length : 활동기간) 등 유연하게 변경 가능.
- 고급화 전략의 플랫폼이라면 Recent(구매 주기) 기준을 좀 더 러프하게 두는것도 좋다.
3. 코호트 및 리텐션 분석
3-1. 코호트 리텐션이란?
코호트란 일반적으로 '공동 특성을 가진 집단' 을 의미합니다.
이때 공통 특성이라 하면,
- 20대 남성 (인구 통계학적 코호트)
- 같은 지역에 같은 시간대에 거주하는 사람 (지역적 코호트)
- 같은 날 같은 프로모션을 통해 가입한 고객 (가입일 코호트)
- 실험 동일 처리 그룹 (Case Cohort Study) (실험적 코호트)
와 같이, 공통 특성을 공유하고 있는 집단끼리 특성을 나누어 보는것을 코호트 분석이라고 합니다.
학부생 때 배웠던 '실험적 코호트' (ex 마시멜로 실험) 처럼 실험 설계자가 임의로 특별한 처방을 취한 군집을 코호트 군집으로 분류하는 것이 대표적이었는데, '마케팅 / 데이터 분석' 에서 일반적으로 사용되는 '코호트' 는 사용자 공통 특성에 따른 매출/행동 분석에 주로 활용되고 있는 것으로 보입니다.
그럼 고객 세분화와 다른게 뭔데? 라고 반문하신다면,
코호트 분석은 세분화 기법 중 시간에 따른 변화를 추적하는데 목적을 둔 분석이라고 말씀드리겠습니다.
- 마시멜로 실험 : 유아기 때 자제력이 높은 군집은, 성장 과정에서 사고력과 수리 능력에 끼치는 긍정적인 영향을.
- 코호트 리텐션 분석 : 어떤 코호트를 갖는 고객들이 지속적인 서비스 사용 / 매출을 만들어내고 있는지를 분석.
실제로, 코호트 리텐션에서 주로 풀고 있는 문제들을 예로 들자면 아래와 같습니다. (데이터리안 참고)
- 어떤 채널을 통해 가입한 고객들이 가장 많을까?
- 유입채널 별 가입 고객들의 1인 결제금액 (ARPU) 이 다를까?
- 어떤 유입채널의 고객들이 가장 많은 매출을 올리고 있을까?
- 어느날에 가입한 고객들의 매출이 가장 높을까?
리텐션에 대해서도 알아보겠습니다.
앞서 미리 언급해버렸지만, 리텐션이란 '고객들이 얼마나 반복적으로 서비스를 이용하고 있는지' 를 분석하는 방법론입니다. 즉 고객들이 얼마나 서비스에 충성하고 있는지, 얼마나 자주 서비스 핵심 가치를 경험하는지를 수치화할 수 있는 중요한 개념입니다.
이때, 반복 사용에 대한 측정은 고객들이 '동일 고객들이 얼마나 자주 서비스를 접속했는지(유저 리텐션)' 또는 '동일 고객들이 월별로 얼마나 반복적으로 매출을 기록했는지(고객 리텐션)' 등을 활용할 수 있습니다.
간단한 예로, 어떤 서비스의 시작 5개월간의 고객 매출 리텐션은 아래와 같이 계산할 수 있습니다.

위의 사례에서는, 가입월이 동일한 고객들을(가입월 코호트) 기준으로 묶어 각 월별 매출 리텐션를 추적하였는데, 이것이 코호트 리텐션 분석입니다. 해석하는 방식은, 가장 첫번째 열부터, '1월 가입자 1000명은 1개월차에 평균 5$, 2개월차에 평균 3$, 3개월차에 평균 1$ 매출을 기록함.' 으로 해석해보시면 됩니다.
리텐션은 특히!
우리 서비스를 반복 이용하는 단골 고객이 누구인가? 이러한 고객이 얼마나 되는가? 를 측정하는 너무나 중요한 개념입니다. 특히, 우리 서비스의 단골이 얼마나 많은가, 어느 고객을 우선 공략하는것이 매출을 더 쉽게 만들수 있는가(적은 비용으로 단골 찾기), 더 나아가, 해당 서비스의 시장 적합성(Product Marketing Fit) 을 평가하는데 중요한 개념이므로, 추가적인 공부가 필요하다면 아래와 같은 사이트를 참고해보시길 바랍니다.
- 데이터리안 - 리텐션이 중요한 이유
- 오픈애즈 - 3가지 계산으로 마스터하는 리텐션
3-2. 코호트 리텐션 차트
코호트 리텐션 그 제체를 궁금해 하셨을 분들도 있겠지만, 대부분은
GA4 나 시각화 도구에서 기본적으로 제공되는 코호트 리텐션 차트가 무엇을 보여주고 왜 쓰는가? 에 대해 궁금해서 이것을 보고계신다고 생각합니다.
예를 들어보겠습니다.
만약 여러분들이 어떤 서비스를 운영중이고, 추가적으로 광고 마케팅 채널 역시 운영중입니다. 이러한 서비스의 매출이 월별로 꾸준히 상승하고 있다면 해당 서비스는 정말 잘 운영되고 있는 서비스일까요?

매출액만 높아진다고 꼭 좋은 신호는 아닙니다.
마케팅으로 유입된 고객들이 실제 서비스를 만족해서 꾸준히 구매하고 있는거라면 좋겠지만, 실제로는 유입 고객들이 한번 서비스를 이용해보고 기겁해서 떠나는데도, 마케팅 유입 고객의 구매로만 매출이 유지되고 있는지도 모릅니다.
그렇기 때문에, (1) 고객들이 꾸준히 유입되고 있는지, (2) 고객들이 반복적으로 핵심 가치를 경험하고 있는지 (3) 서비스가 지속적으로 개선되고 있는지 를 평가해볼 필요가 있습니다.
자 이제 아래의 <코호트 리텐션>으로 쪼개서 매출을 분석해 보겠습니다.

서비스 5개월간 월별 동일하게 1000명씩의 꾸준한 유입이 있었고 ,
첫 1월 가입자들 대비, 5월로 갈수록 가입 이후 첫 1개월차 매출액은 5$ 에서 9$ 까지 증가했습니다.
또한, 각 월 가입자들의 매출액 리텐션 역시 꾸준히 증가하고 있음을 확인할 수 있습니다.
즉, 해당 서비스는 꾸준하게 고객 리텐션이 증가하는 방향으로 성장하고 있음을 의미합니다.
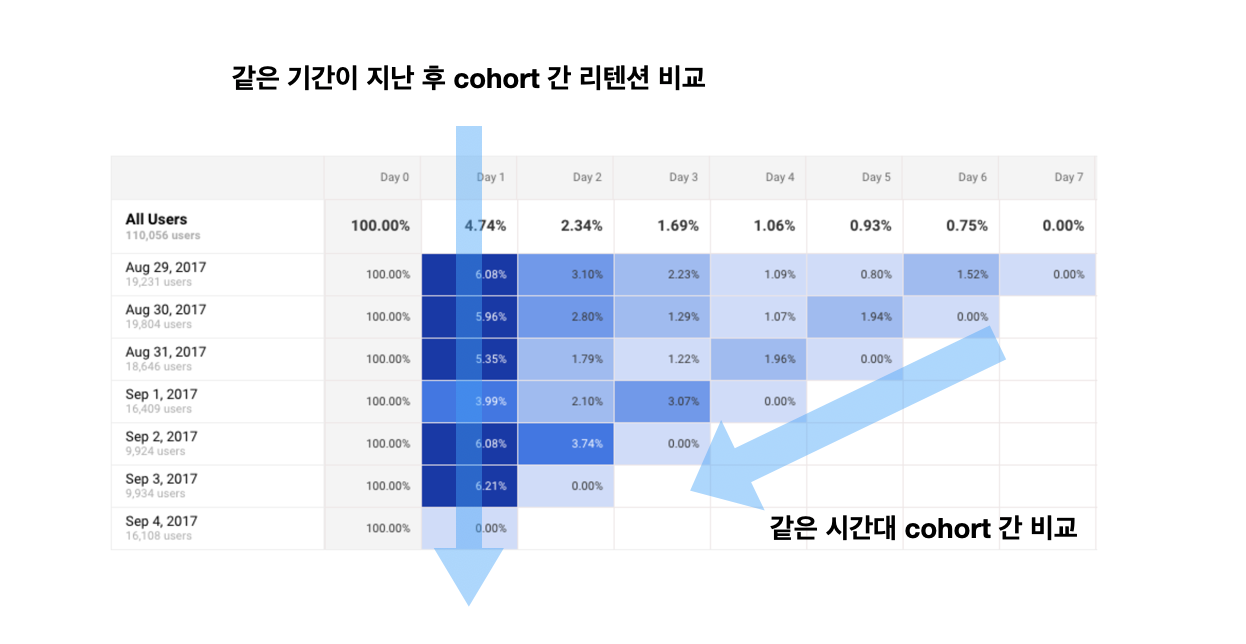
<코호트 리텐션 차트>는 이러한 분석 내용을 더 직관적으로 보여주는 툴입니다.
특히 가입 코호트별 리텐션을 히트맵으로 보여주기 때문에 수치적 비교를 좀 더 직관적으로 비교할 수 있는 장점이 있습니다. 또한 아래의 보조 화살표와 같이, '같은 기간이 지난 후 코호트간 리텐션 비교' 를 통해서 서비스 가치가 지속적으로 증가하는지, '같은 시간대 코호트 비교' 를 통해서 해당 월의 매출이 어느 코호트에서 특히 기인했는지를 빠르게 파악할 수 있습니다.
4. 고객생애가치
4-1. 고객 생애 가치 정의 및 계산
CLV = LTV 는 표현은 살짝 다르지만 각각 Cusotmer Lifetime Value 의 줄임말으로서 고객 1명으로부터 우리 서비스가 얻게 되는 총 기대 가치를 의미합니다. (이후에는 LTV로 통일해 사용하겠습니다.)
흔히 ARPU, ARPPU 와 혼동해서 오용할 수 있지만, 이는 기간(일별/월별)을 두고 발생한 매출에 대해 각 고객당 매출액으로 나누는것이고, LTV는 한 고객이 서비스 평생 이용기간동안 발생하는 총 수익의 기댓값을 의미합니다.
이는 아래와 같은 의의를 갖습니다.
- 서비스 유지 측면에서 고객 총 가치 대비 고객 획득 비용의 수익성 계산.
- 총 매출액이 아닌, 고객 생애 가치가 더 높은 마케팅 채널에 더 집중 투자.
- 기존 고객의 생애가치를 높여 매출 증진, 꾸준히 활동 고객의 생애 가치를 모니터링.
특히 고객 생애가치는 개별 고객 생애 매출 - 고객 획득비용을 포괄하는 개념이므로, 고객 1명당 서비스 수익성을 직관적으로 빠르게 평가할 수 있는 중요한 지표입니다.
'컨버디드' 책의 표현을 빌리자면, 고객 생애 매출보다 획득비용이 높은 서비스는
'50$ 짜리 상품을 구매하는 고객에게, 100달러짜리 지폐로 포장한 박스를 주는 것보다 못하다.'
고 표현할 정도입니다.
고객 생애 가치를 계산하는 방식은 사람마다 조금씩 다르지만, 주로 활용되는 식은 아래와 같습니다.

- M: 고객 1인당 평균 매출. 보통 1년 단위로 계산한다.
- c: 고객 1인당 평균 비용. 보통 1년 단위로 계산한다.
- r: 고객 유지 비율 (retention rate), 즉 어떤 고객이 그 다음 해에도 여전히 고객으로 남아 있을 확률
- i: 이자율 또는 할인율
- AC: 고객 획득 비용 (Acquisition Cost). 고객이 첫 방문 또는 첫 구매를 하도록 하는데 드는 비용
조금 복잡해 보일 순 있지만, 등비수열을 활용한 매우 간단한 수식입니다.
만약 고객별로 '1인당 평균 매출액', '1인당 평균 비용', '고객 유지 비율' 이 특정 값으로 수렴한다면
아래와 같이 등비수열의 합으로 표현할 수 있고, 이를 정리하면 위와 같은 LTV(=CLV) 식이 유도됩니다.
$$ LTV=ARPU+ARPU×r+ARPU×r2+...=ARPU1−r $$
4-2. 고객 생애 가치 계산 대체
고객 생애 가치는 서비스 수익성 측면에서 간단하고도 중요한 지표라고 말씀드렸지만,
바로 위의 가정, 즉, '1인당 평균 매출액', '1인당 평균 비용', '고객 유지 비율', '1인당 평균 고객 획득 비용' 이 특정 값으로 수렴한다라는 가정 때문에 현실에서 그대로 적용하기 매우 어렵습니다.
이러한 기존 LTV 계산의 단점을 보완하기 위해서, 크게 두가지의 대체 방안을 적용할 수 있습니다.
(1) 고객 생애 매출(LTR) 지표 모니터링
(해당 내용은 '그로스 해킹(양승화 지음)' 의 내용을 참고했습니다.)
위 등비수열 기반의 LTV는 1인 평균 매출액(+)과, 1인 평균 고객 획득비용(-)을 동시에 집계하여 '수익'을 계산합니다. 그러나, 서비스 수익성이 개선되고 있는지를 모니터링할 때, 1인 평균 매출액(LTR)만으로도 간단하게 계산해볼 수 있다는게 그 의도입니다.
아래 예시에서, '2020년 1월' 가입자를 예로 들어 보겠습니다. 만약 8개월 이내에 모든 고객이 이탈했다고 가정하면, 해당 코호트의 월별 1인당 결재 평균액을 기준으로 2020년 1월' 가입자의 1인당 평균 매출액(LTR) 을 예측할 수 있습니다. 이러한 방식을 반복하여 각 월별 LTR을 예측하여, 고객 획득 비용(CAC) 기준으로 서비스가 얼마나 수익성이 타당한지 지속적으로 모니터링할 수 있습니다.
물론, 해당 가정처럼 모든 코호트 내 고객들이 2020년 9월 이후 모두 이탈했다고 판단하기는 어렵지만, 계산 자체가 단순하고 반복가능하기 때문에, 지속적으로 서비스 수익성을 모니터링할 수 있습니다.

(2) 모델링 기반 LTV 예측
LTV, LTR 을 계산하는데 있어 특히, '1인당 평균 매출액(ARPU)', '고객 유지 비율(retention)' 이 가장 중요하다는 것을 어느정도 느끼셨을 것입니다. 이 두가지만 잘 추정하더라도 LTV 예측 정확도는 매우 높아집니다.
링크의 사례는 NC 소프트의 게임 고객 LTV 추정 내용이며, 평균 매출액은 이동평균으로, 유지비율은 ML 모델링으로 계산하는 방식이 특이해서 사례로 들고 왔으니, 혹시 관심이 있으신 분들이라면 추천드립니다.
https://danbi-ncsoft.github.io/works/2020/03/16/works-mobile_mkt_ltv.html
게임 고객 LTV 추정하기
danbi-ncsoft.github.io
내용이 너무 길어져 '장바구니 분석' 및 '추천 시스템' 은 다음 포스팅에서 작성해보도록 하겠습니다.